NSE Week 7: Intrusion detection and prevention
IDPS
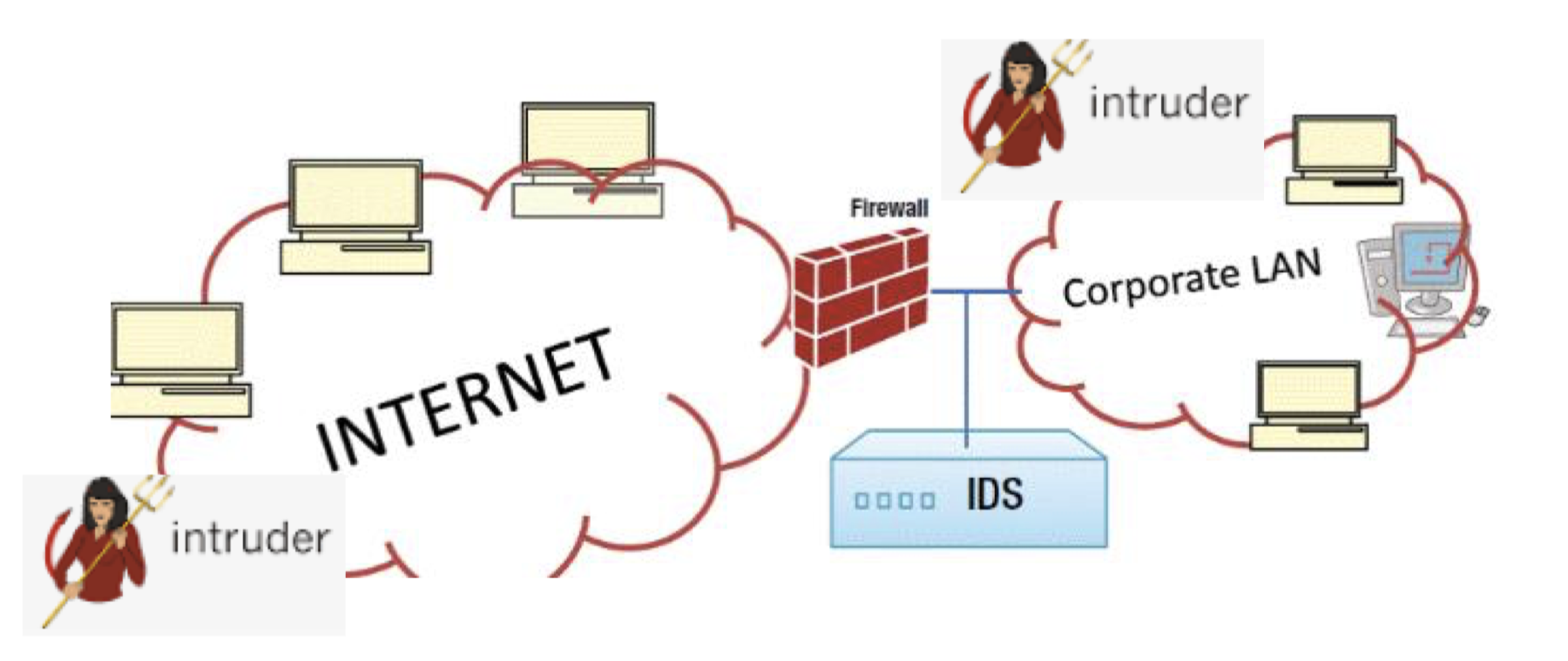
IDPS vs firewall
Why we need Intrusion detection since we already have firewalls?
-
IDS的主要目的是检测并报告任何网络中的入侵尝试
-
IDS是建立在firewall之后的,还记得我们之前在firewall中提到的三层内网保护机制吗,IDS就作为街道巡逻来识别可疑的入侵者
-
Firewall主要是将外敌抵御在城墙之外,而IDS就负责抓住潜伏进来的内鬼
Three classes of intruders
- Masquerader 伪装者
- Masquerader是一个外部人员,没有任何权限来使用计算机,但是却通过外部手段进行渗透,操控了合法用户的账户,可以被看作是一个outsider
- Misfeasor 渎职者
- Misfeasor是一个合法的用户,但是却做了超出其权限活着规定的事情,可以被看作是一个insider
- Clanderstine user 秘密用户
- Clanderstine user通过获取获取系统的高级权限,进而破坏系统的防御措施,可以是insider活着outsider
IDPS Definitions
- Intrusion
- 未经授权的对于计算机资源的访问
- Intrusion detection
- 检测对于系统活着网络未经授权的访问
- Intrusion detection system (IDS)
-
就像是网络中的杀毒软件
-
组成:sensors, alerts; 检测如前以及报告检测到的如前
-
- Intrusion prevention system (IPS)
- IPS 就是一个IDS并且自动对检测到的入侵做出反馈的系统:
- 关闭入侵者的网络连接
- 尝试反溯源入侵者
- 对抗攻击
- IPS 就是一个IDS并且自动对检测到的入侵做出反馈的系统:
IDS与IPS配合使用,一般来说IDS在IPS的后面辅助其更好的加强安全
Approaches to intrusion detection
那我们具体应该如何识别一次入侵呢?
- 最基础的方法就是密切监控所有合法用户的行为,一旦出现异常的行为,就很有可能是一次入侵
但是入侵行为却和普通的行为有很大的重叠
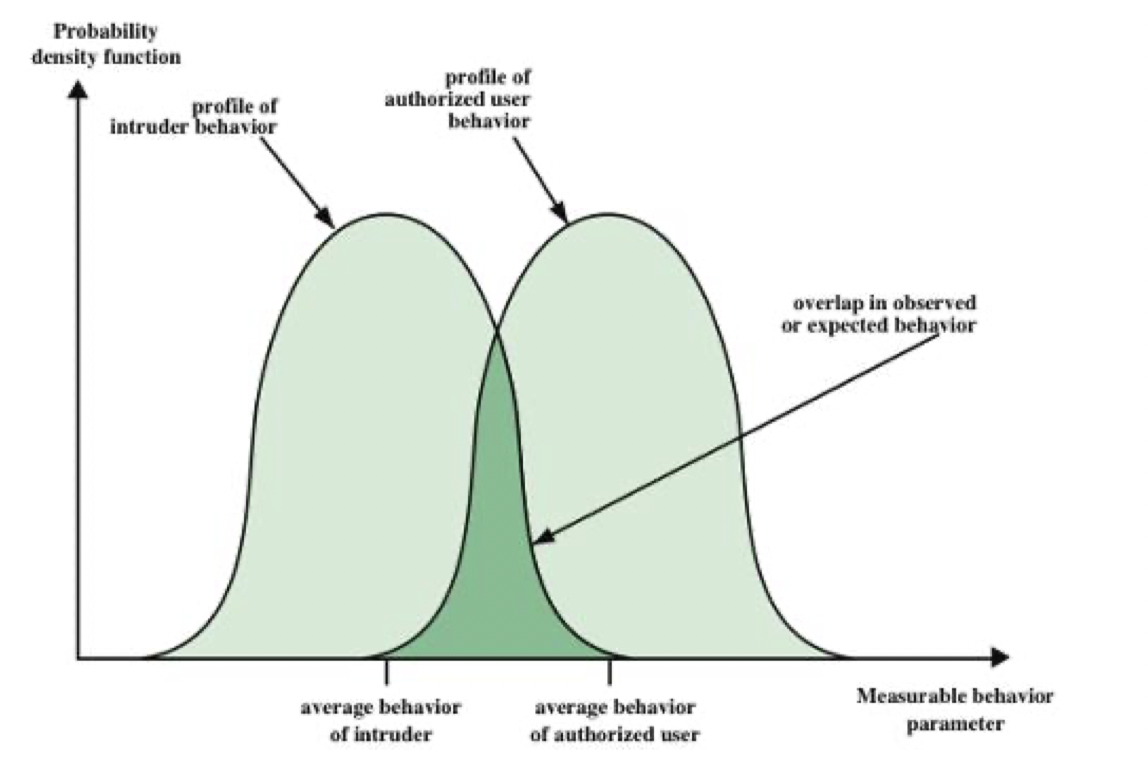
因此检测很有可能会出现问题,我们用machine learning中曾经用过的概念来解释入侵检测
前提:在这里,一次positive就表示,IDS识别了一次intrusion
-
False positive 就是表示一个授权的用户的正常行为被错误的认为是了入侵,检测条件较为宽松的IDS更容易检测到更多的入侵,但同时也会遭致很多的false alarms, completeness
-
False negative 就表示一次入侵没有被识别为入侵,检测条件如果较为单一,那么相对而言检测到的入侵会更加准确,但是却会遗漏很多的入侵,soundness
-
-
Reputation detection: - 观察主机是否与曾经行为不良的用户进行通信
-
Anomaly-based detection: - 首先定义系统内正常的行为,然后检测那些不正常的行为,一般使用机器学习来进行训练和识别
-
Misuse-based detection: - 预先定义不良的行为作为模版,然后用这些模版进行匹配检测
-
Reputation based
主要目的是为了观察主机是否与曾经行为不良的用户进行通信
那么如何来判断这些不良的用户呢?
一半了是基于OSINT,开源的情报以及一些私有的黑名单来进行筛选识别
- Malware Domain List (MDL)
- Google Safe Browsing
- Spamhaus Block Lists
- PhishTank
Misuse based
预先定义不良的行为作为模版,然后用这些模版进行匹配检测
- 也被称为 signature detection,通过识别几个特定的signature来进行匹配检测
- 依赖于恶意行为模型models of malicious behaviour
- 同样使用开源情报:Indicators of Compromise (IoC) & Indicators of Attacks (IoA)
- IoC/IoA/signature 就如同firewall中的blacklist一样,用来匹配那些恶意行为
-
Indicators of Compromise (IoCs)
IoC一般是作为取证数据,从日志或者文件中提取出来的恶意行为特诊
- 可以被分为host-based或者是network-based
- 甚至可以是很复杂的shellcode
- IoC主要关注点在已经发生过的入侵,从日志,文件等信息中来识别
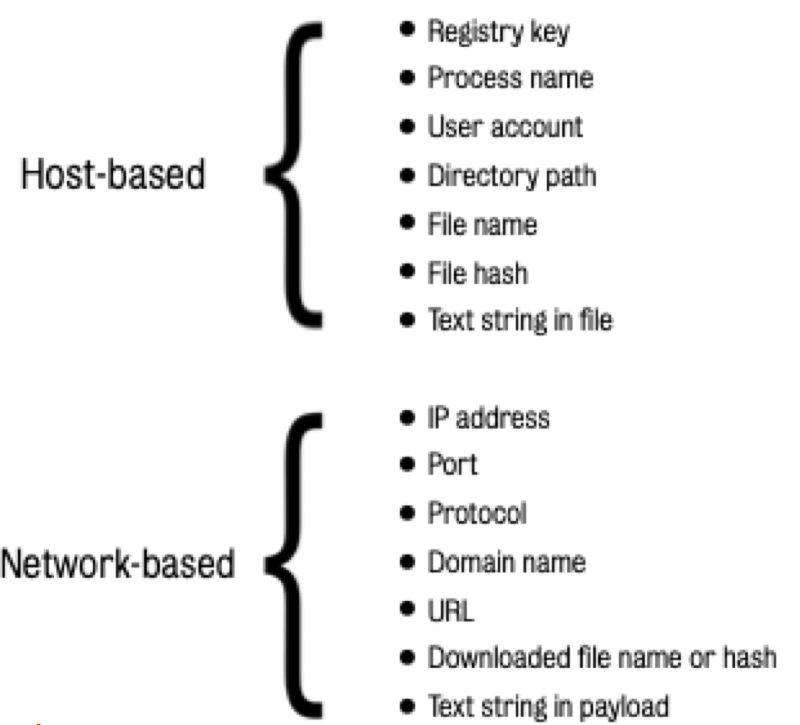
Indicators of Attacks (IoAs) : - IoAs就关注于正在发生的入侵
-
Misuse-based detection: pros and cons
Misuse-based detection的例子:
(traffic source.ip = destination.ip) and (source.port=destination.port)
这就是一个很典型的异常行为的匹配与判断
Advantages : 1. 较少的false alarms 2. 每次的alerts都会有对应的解释(匹配了什么模型) 3. 速度很快 4. 不惧怕evasion,因为是预先设定好的,不会更改
Disadvantage : - 只能检测已知的攻击(APT,zero-day就束手无策了)
- 需要不断更新换代 <br/> - 对于over-stimulation attacks来说是错误的 <br/>
Anomaly based
首先定义系统内正常的行为,然后检测那些不正常的行为,一般使用机器学习来进行训练和识别
- 需要先收集一段时间的数据来定义正常的行为
- 然后将统计测试的结果应用到检测用户的行为来判断是否合法
- 阈(yù)值检测 Threshold detection:对各种时间的发生频率进行定义,查看是否出现异常
- 基于账户 Profile based:为不同用户的行为进行记录统计,来观察每个用户行为的变化
- 侧重于过去的行为,然后检测重大的变化
- 可以被认为是白名单检测,默认不信任所有的行为
-
Statistical test
- Mean and standard deviation 平均值和标准差
- 通过一段时间的数据来进行计算
- 可以运用到很多参数上
- 不适合单独在IDs上使用
- Multivariate calculation
- 用来决定几个变量之前的关系(例如处理时间,数据占用,登录频率等)
- 通过对于变量关系的分析可以更好的进行分类
- Markov process
- Estimates transition probabilities among various states
- Efficient in describing protocol run
- Time series model
- 根据时间次序进行计算
- 可以用来检测一些活动进行的太快或者太慢
- Mean and standard deviation 平均值和标准差
-
Pros and Cons
Advantages : 1. 可以检测那些从来没遇到过的攻击 2. 不需要主动去更新
Disadvantage : 1. 很难进行配置以及需脸 2. 定义异常的行为为恶意的有时候也不完全准确 3. 会产生很多的 false alarms 4. 消耗大量的资源
Other IDS classification
- 根据时间Timeliness:
- Real-time(实时在线运行)
- Non real-time (离线模式,定期进行)
- 反应措施 Response type:
- Passive (被动的,只有检测到了才会发出警告)
- Active (主动封锁恶意的流量)
- State-dependency
- Stateful analysis(结合上下文的)
- Stateless analysis
- System type:
- 软件
- 硬件
- Topology 拓扑范围类型
- Host IDS (HIDS)
- Network IDS (NIDS)
- Distributed IDS (DIDS)
- 观察和检测整一个网络利用多种检测模式
HIDS/NIDS/DIDS
-
Host IDS (HIDS)
专注于本机的数据 NIC网卡需要处于non-promiscuous mode,即不会接受与自己无关的数据包,进而缩小检测范围
检测的范围:
- Logs 日志
- System calls 系统指令
- Host activities 用户行为
只关注本地服务
-
Network IDS (NIDS)
专注于网络内的所有主机 NIC开放promiscuous mode,接受所有的数据包
通常会部署在:
- choke points(firewall)
- DMZ
- Internal network
Traditional deployment : - IDS设备连接在trunk points (e.g., firewall)上,来检测所有的网络流量,检测攻击,但没有防御手段
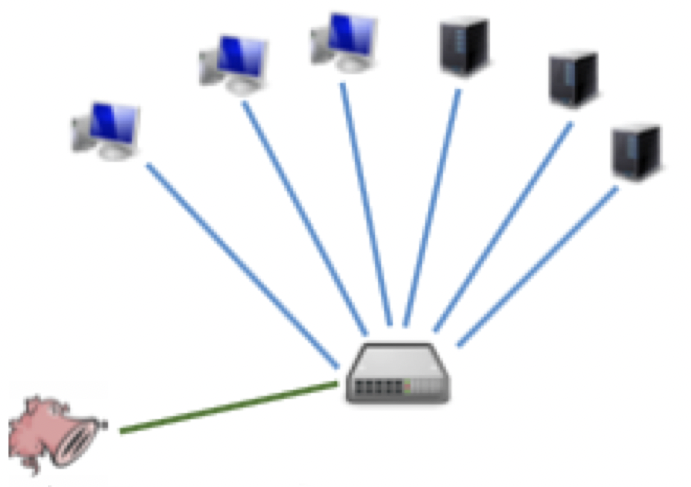
Inline deployment :
IDS设备直接与设备相连接,可以进行检测和防御,例如IPS
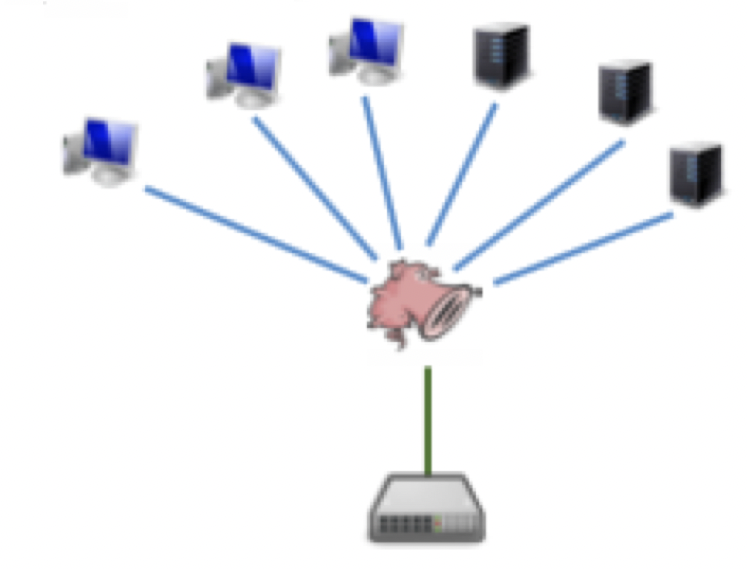
-
Distributed IDS (DIDS)
利用多个sensors(HIDS,NIDS)来收集数据,然后再汇总到中心的管理器上
管理员综合分析所有的事件来进行分析判断
会部署在专用的外部网络上,例如VPN
我们在CFC中就曾经遇见过类似的内容
Security Information and Event Management就可以统一收集并管理所有的数据
- Host会在后台运行监控系统,然后将收集到的数据发送到中央的管理服务器上(外部网络,VPN)
- 中央的管理服务器收集所有的事件报告(从内网中),然后综合分析来入侵检测分析
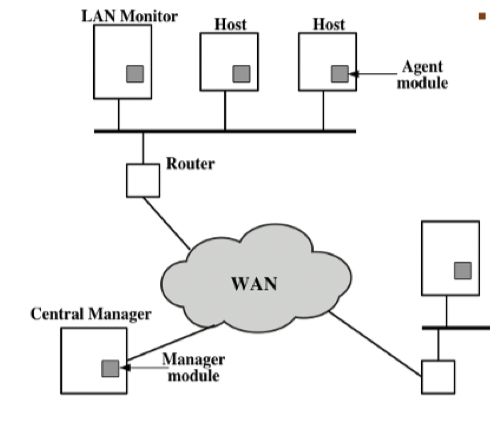
-
IDS是如何工作的
-
Input information 信息输入
- Application-specific information 应用数据
- Host-specific information: 本地日志,系统文件变化,系统命令调用
- Network specific information: 数据流量
-
Intrusion detection policies
- Known bad: blacklist 预定义的攻击模型
- Reputation-based detection
- Signature-based/rule-based/misuse-based detection
- Known good: 报告任何异常情况
- Anomaly-based detection
- Known bad: blacklist 预定义的攻击模型
-
入侵报告
- passive response (检测报告)
- active response (主动封锁连接)
-
- Alert data: IDS alerts
- Log data: complete host logs
- Statistical data: network stats
- Session data: 5-tuple flows
- Packet string data: e.g., HTTP headers
- Full packet capture: PCAP files
-
- Packet capture: tcpdump, wireshark
- Session data: netflow, IPFIX (Internet Protocol Flow Information Export)
- Session string: URLsnarf
- Logs: syslog
-
Measuring performance
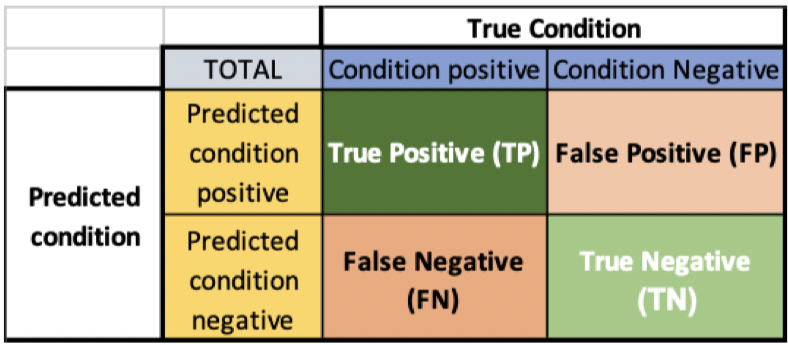
- True positive: 检测到的入侵是真的
- False positive: 检测到的入侵是假的
- True negative: 检测到的合法行为是真的
- False negative: 检测到的合法行为是假的,其实是入侵
Sensitivity (True positive rate, probability of detection): measures the proportion of positives that are correctly identified
Specificity (True negative rate): measures the proportion of negatives that are correctly identified
Sensitivity = True positive rate = Precision = TP / (TP + FP)
-
it reflects the machine learning algorithm’s performance on “How many times you are right?”, TP + FP indicates the total sample are labeled by ML as malware (positive)
Recall = TP / (TP + FN), it reflects “How many malware found by you”, TP + FN means all the actual malware within the dataset
Specificity = True negative rate = TN / (TN + FP)
Base-rate fallacy 基率谬误
指的是人们在考虑事件的概率的时候往往没有考虑全部的信息,而是选择那些个性化的信息而草率的出结论,以偏概全
A & B 是不同的事件
- P(A|B) 是一个条件概率,顾名思义,是在一定条件下,某一些时间发生的概率:当B发生的情况下,A发生的概率
- P(B|A) 是一个条件概率:当A发生的情况下,B发生的概率
- P(A) & P(B) 是A & B单独各自发生的概率
Bayes’ theorem
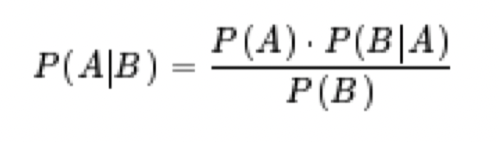
根据贝叶斯定理,P(A|B) * P(B) = P(B|A) * P(A)就是A与B同时发生的概率
可以有效的综合多个概率,从而得出一个更为可靠的综合概率
我们假设:
-
I 为入侵行为
-
¬I 为非入侵行为
-
A 为出现入侵警告事件
-
¬A 没有出现入侵警告事件
-
True positive rate or detection rate: P(A|I),在入侵确实发生的情况下,发出警告的概率
-
False positive rate of false alarm rate: P(A|¬I),在没有发生入侵的情况下,发出警告的概率
-
False negative rate: P(¬A|I) = 1 - P(A|I),在入侵确实发生的情况下,没有发出警告的概率
-
True negative rate: P(¬A|¬I) = 1 - P(A|¬I),在没有发生入侵的情况下,没有发出警告的概率
-
P(I|A): 在发出入侵警告事件的情况下,真的有入侵事件的概率
-
P(¬I|¬A): 在没有入侵警告事件的情况下,确实没有入侵的概率
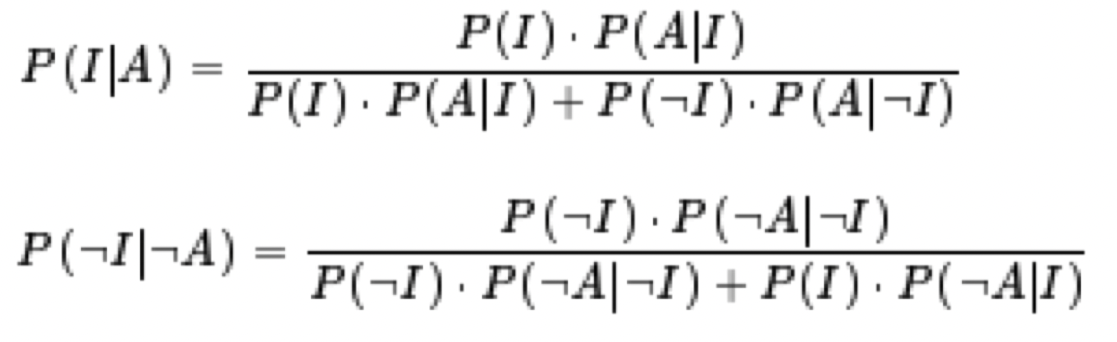
我们假设一个网络管理员在过去的一年中,在每10,000个活动中能检测到1个真实的入侵,继续利用上面的事件,也就是:
- P(I) = 1/10000
同时这位网络管理对自己的工作十分骄傲,因为他从所有入侵中亲自发现了被检测系统遗漏的5%的入侵,也就是:
- P(¬A|I) = 5%
但管理又对检测系统非常的不满,因为其不仅会遗漏入侵,还有3%的入侵警报事件是误报,也就是
- P(A|¬I) = 3%
如果我们要计算一个警告真的是入侵的概率,也就是P(I|A),就可以套用上面的公式 P(I|A) = P(I) * P(A|I) / P(I) * P(A|I) + P(¬I) * P(A|¬I)= ((0.0001 * 0.95) / ((0.0001 * 0.95)+(0.9999*0.03)) = 0.00315 –> 0.32%
Honeypots
Honeypots as a deception technique
Why we need honeypots, since we already have firewalls and IDPS? Firewall和IDPS更多的是拦截和阻断攻击者的攻击,但是如果我们想更多的了解attacker,从而提前掌握潜在的威胁,那么我们就需要用到Honeypots,蜜罐,用来引诱攻击者暴露更多的信息:
- Honeypot 蜜罐
- 是一个陷阱其实放置了检测以及反制手段来获取那些未经许可的访问的信息
- 同时也作为诱饵,使攻击者原理重要的系统
- 学习未知的攻击
- 学习入侵者的行动模式
- 从而更好的预测和抵抗未来的攻击
蜜罐没有实际的生产价值,其知识为了防范入侵
- 里面充斥着一些伪装的信息,来引诱攻击者进行入侵
- 因此合法的用户不会与其通信,那么所有的通信只会是扫描,入侵或者给农机
- 进而我们可以收集攻击者的活动
- 并部署一些看起来有价值的信息来诱导攻击者长时间的驻留的系统内,以便我们更好的手机信息
- 尽量要让攻击者成功入侵,这样才能使他们驻留,并留下痕迹
- 同时也不能太容易入侵,最好能让攻击者感到有挑战性
Honeypots deployment and classifications
-
Deployment
蜜罐一般会被部署在DMZ上,当然也可以在边界路由器之外(指外网),或者内网也可以。
进而部署虚拟的环境,同时营造出尽可能真实的系统环境,通过深度的监控来手机攻击者的信息
-
Classification
根据目的 : - Production honeypots 蜜罐产品 - 为企业的网络环境提供蜜罐产品 - 更容易部署和使用 - 在易用和信息收集量之间做取舍 - Research honeypots 研究型蜜罐 - 提供更全面的攻击信息 - 更难部署,因为考虑到没有那么专业的开发力量来优化 - 通过更加全面地研究攻击,进而找到更好的解决方法
根据互动的程度 : - 提供较少互动的蜜罐 - 只模拟运行一小组服务和应用 - 不能被获取所有权限 - 攻击者的互动被限制 - 通常是用在产品型蜜罐上 - 优点:风险低,容易部署 - 缺点:收集到的信息较少,因为互动少
- 提供较多互动的蜜罐 <br/> - 使用真实的操作系统和应用 <br/> - 攻击者可以获得所有网络和系统的访问 <br/> - 通常用在研究型蜜罐上 <br/> - 优点:可以获取更多的信息 <br/> - 缺点:较高的风险,并且维护的成本更高 <br/>根据实现的方法 : - Physical honeypot 物理蜜罐 - 网络上连接的真实设备 - Virtual honeypot 虚拟蜜罐 - 模拟主机进行互动 - 一个主机可以同时维护和运行多个虚拟蜜罐 - 通常可以提供更多的互动,因为虚拟环境更为安全
根据互动的方向 : - Server honeypots 服务器蜜罐,开启服务
- Client honeypots 客户端蜜罐,连接服务器的服务 <br/>
Honeypots phases
最好的方法:
- 较高的堡垒化网络
- 每一个数据包都进行保存,便于分析学习
Phases:
- Data control
- Data capture, 捕捉attacker所产生的各种data
- Data analysis,分析这些data,学习攻击者的互动
-
Data control
蜜罐通过与攻击者进行通信(via protocols)来诱导他们做出行动,留下踪迹
- Bandwidth throttling 宽带限流
- 由ISP主动给网络服务降速,从而增加访问蜜罐消耗的时间成本,减少了对其他用户造成危害的时间
- Bandwidth throttling 宽带限流
-
Data capture
蜜罐将会监控被记录所有攻击者在蜜罐上所进行的活动,进而集中存储
- Network activity
- Application activity
- System activity
-
Data analysis
蜜罐分析所有收集到的活动数据
- Human-driven analysis
- tester或者researcher使用自动化工具来处理数据进行分析
- Machine-driven analysis
- 假设网络连接都是恶意的和异常的
- Human-driven analysis
Case study: catch the ratter
RAT: remote administration tools
通过让攻击者利用RAT来获取全部虚拟机的权限来手机信息并研究他们的行为:
- Capture audio from microphone
- Capture video from webcam
- Log keyboard input
- Browse files on machine
Honeytokens
Honeytokens是一种蜜罐的形式,但是并不是计算机操作系统,但也许是一个:
- 不使用的邮箱地址
- 虚假的数据库
这些虚假的设备不再于使用,而在于被入侵和破坏
比如在数据库中有一条虚假的信息,没有任何实际的价值,在生产过程中也不会访问这条数据,但是一旦被访问了,就表示有入侵发生了。
这种方式更为简单易用,不需要部署复杂的蜜罐系统,也可以识别出攻击
<2022-05-29 Sun 10:52>