NSE Week4: Hijacking and poisoning
TCP Session Hijacking
What is Hijacking 劫持?
指的是劫取其他人的东西,特别是在运行的时候。
Hijacking 劫持与spoofing的不同点在于:
- Hijacking 是劫持一个已经存在的TCP连接
- 而Spoffing则是通过修改IP header来发起新的连接进行欺骗
-
Off-path v.s. On-path adversaries
顾名思义,就是判断发起劫持的主机是否在连接的两台主机的路由上:
- 如果在路由上,那么就是On-path, 这种劫持更为强大,可以直接注入错误的信息,但是却很难扩大规模
- 如果不在路由上,那么就是Off-path,这种劫持就无法直接注入错误的信息了
TCP connection
如何唯一识别一个TCP连接呢? (source IP address + port number) + (destination IP address + port number)
Port number就指示了双方所运行的应用层的应用
-
TCP three-way handshake
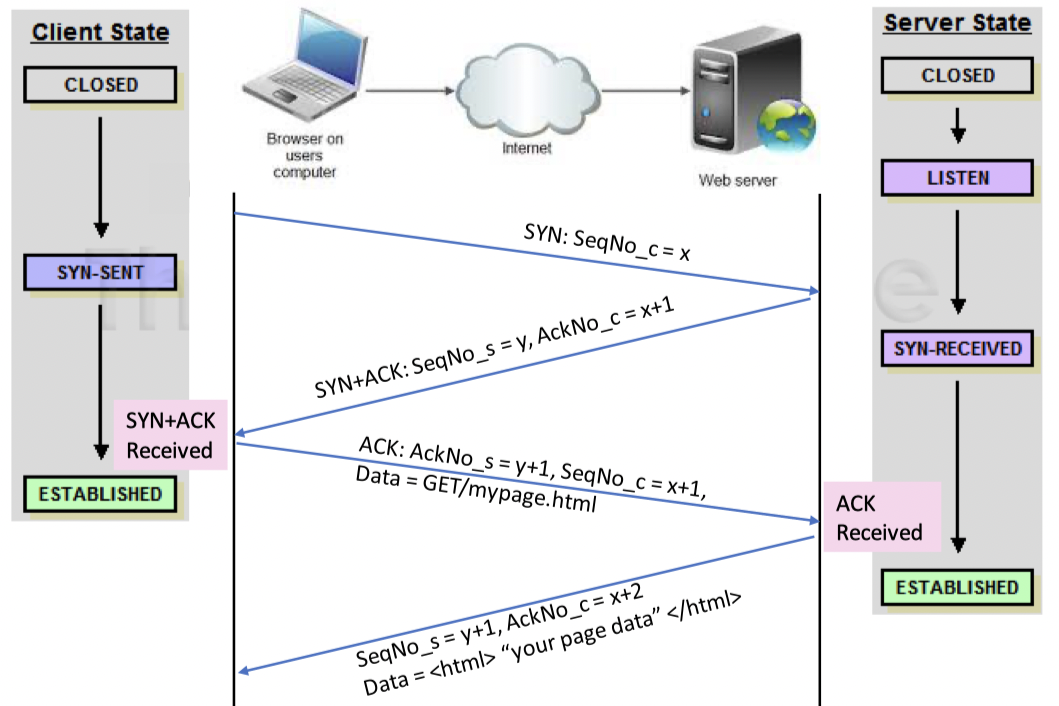
通过不断增加Sequence number以及Acknowledgement number来实现握手,以及后续的通信
-
How does an attacker hijack a TCP session?
攻击者需要构造一个TCP segment来满足sequence number & acknowledgement number的回复
那么需要的信息有
- Source IP address + port number (easy to get)
- Destination IP address + port number (easy to get)
- Sequence number (如果攻击者在路由上的话就不会很难,因为可以通过获取到的通信数据包来推测)
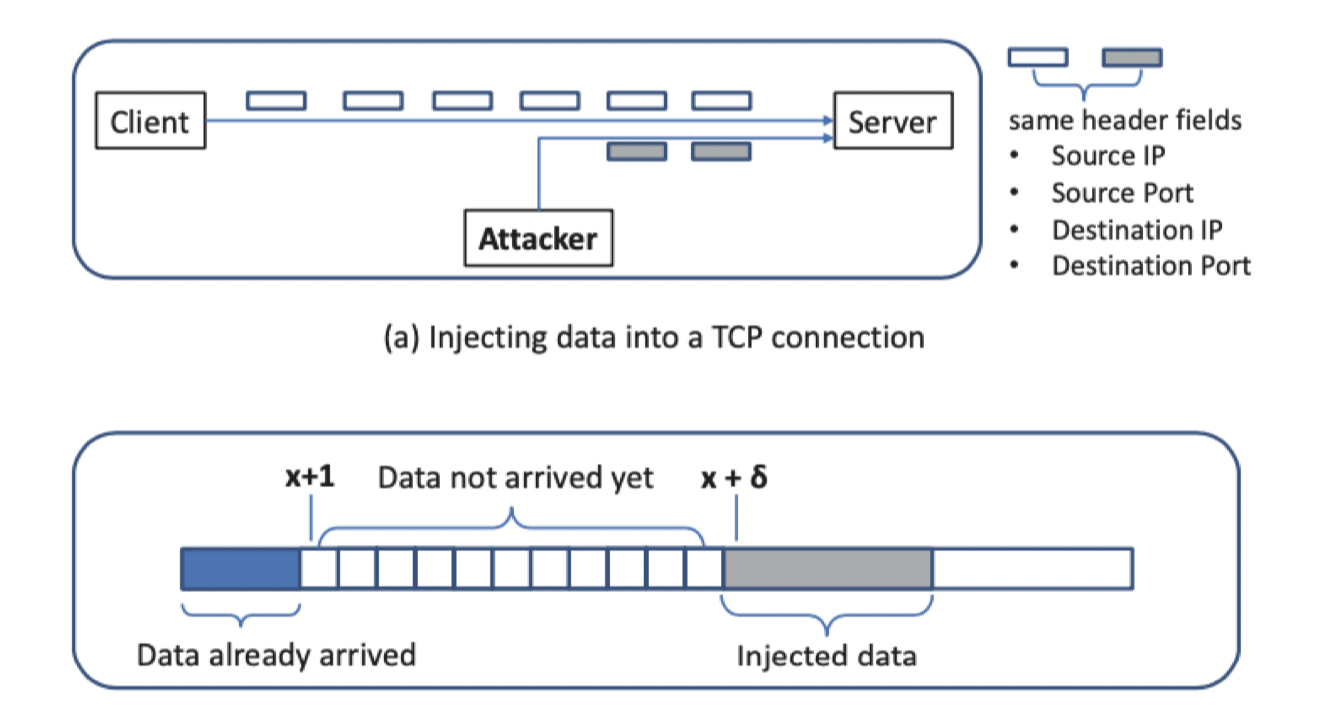
Sequence number可以是捕捉到的数据包的sequence number + 1 亦或是+ n,只要n不要太大,接收者都会将这些数据包保存在buffer中,等待中间“未接收到”的数据包
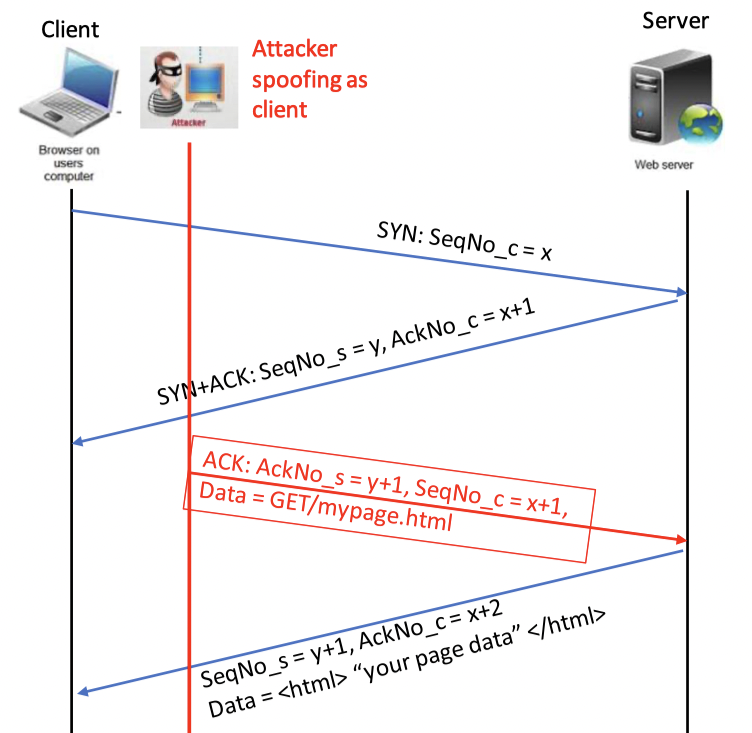
TCP on-path connection hijacking
TCP on-path connection hijacking, attacker可以更方便的接收到通信的sequence number和acknowledgement number
只需要合理增加数字,就可以实现劫持,并发出恶意修改的数据:
- 嗅探数据包
- 预测sequence number (client -> server; server -> client)
- 注入恶意数据
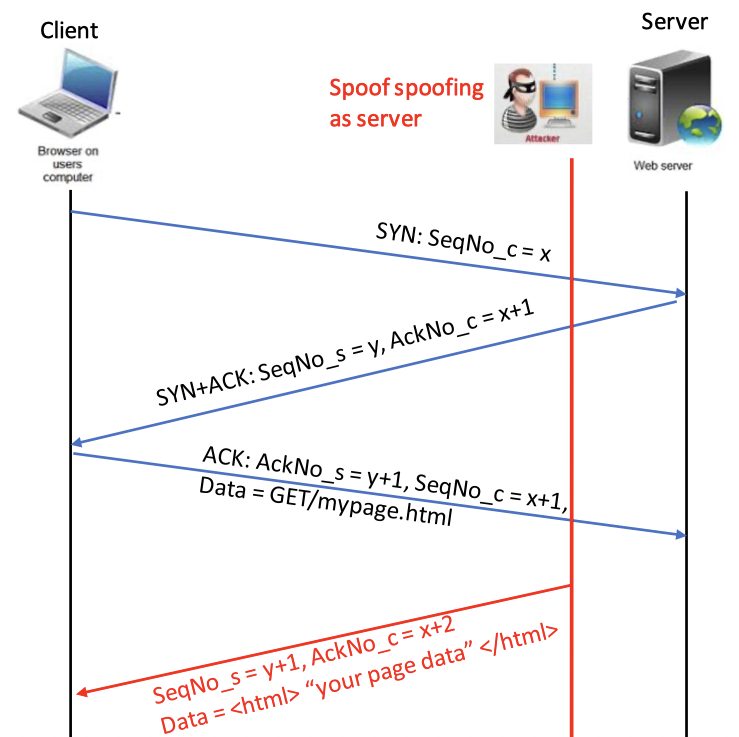
TCP off-path connection hijacking
由于攻击者的主机并不在连接的路由上,因此attacker没有办法获取任何当前连接的信息,因此其需要主动发起一个连接,然后在劫持这个连接,同时返回合法的sequence number,但这一次因为无法进行嗅探,只能进行猜测
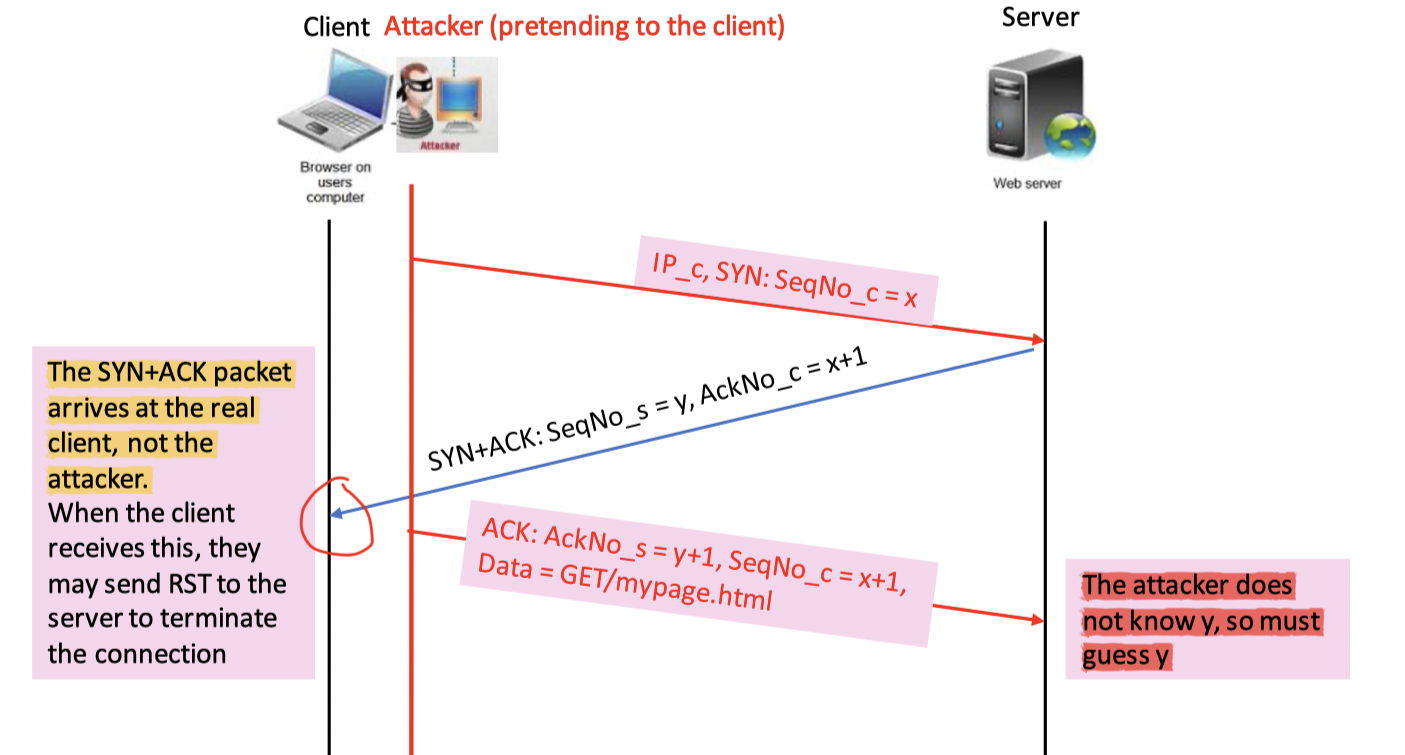
-
How to guess the initial sequence number
这里利用的就是一些操作系统没有使用规范的标准来实现TCP连接
RFC 793 (TCP specification) :
When new connections are created, an
initial sequence number (ISN)generator is employed which selects a new32 bit ISN. The generator is bound to a 32 bit clock whose low order bit is incremented roughly every 4 microseconds.Thus, the ISN cycles approximately
every 4.55 hours. (4 microseconds x 2^32)Since we assume that segments will stay in the network
no more than the Maximum Segment Lifetime(MSL, defined as 2 minutes in RFC 793) and that the MSL is less than 4.55 hours we can reasonably assume that ISN’s will beunique. [i.e., sequence numbers should not repeat for at least 4.55 hours]The purpose is to ensure undelivered packets from previous connection that arrive late do not overlap with current connection
总结:在RFC 793的标准下,sequence number的递增周期就是4.55 hours,这超出了最长的连接时间(2mins),因此无论怎么递增,都基本不会从头开始,可以将所有的sequence number看作是unique唯一的
Unfortunately, BSD Unix TCP/IP stack did not adhere to these recommendations : - The sequence number for BSD TCP/IP stacks increases by 128,000 every second and by 64,000 for every new TCP connection. - Such a sequence is relatively easy to predict and can be much more readily exploited than one which follows the RFC standard
可是在BSD Unix中,却没有按照标准实现,而是变成了sequence number每秒增加128,000,每一个新的连接增加 64,000, 这放宽了预测的时间以及缩小了范围,使sequence number很容易被预测
-
TCP initial sequence number attack
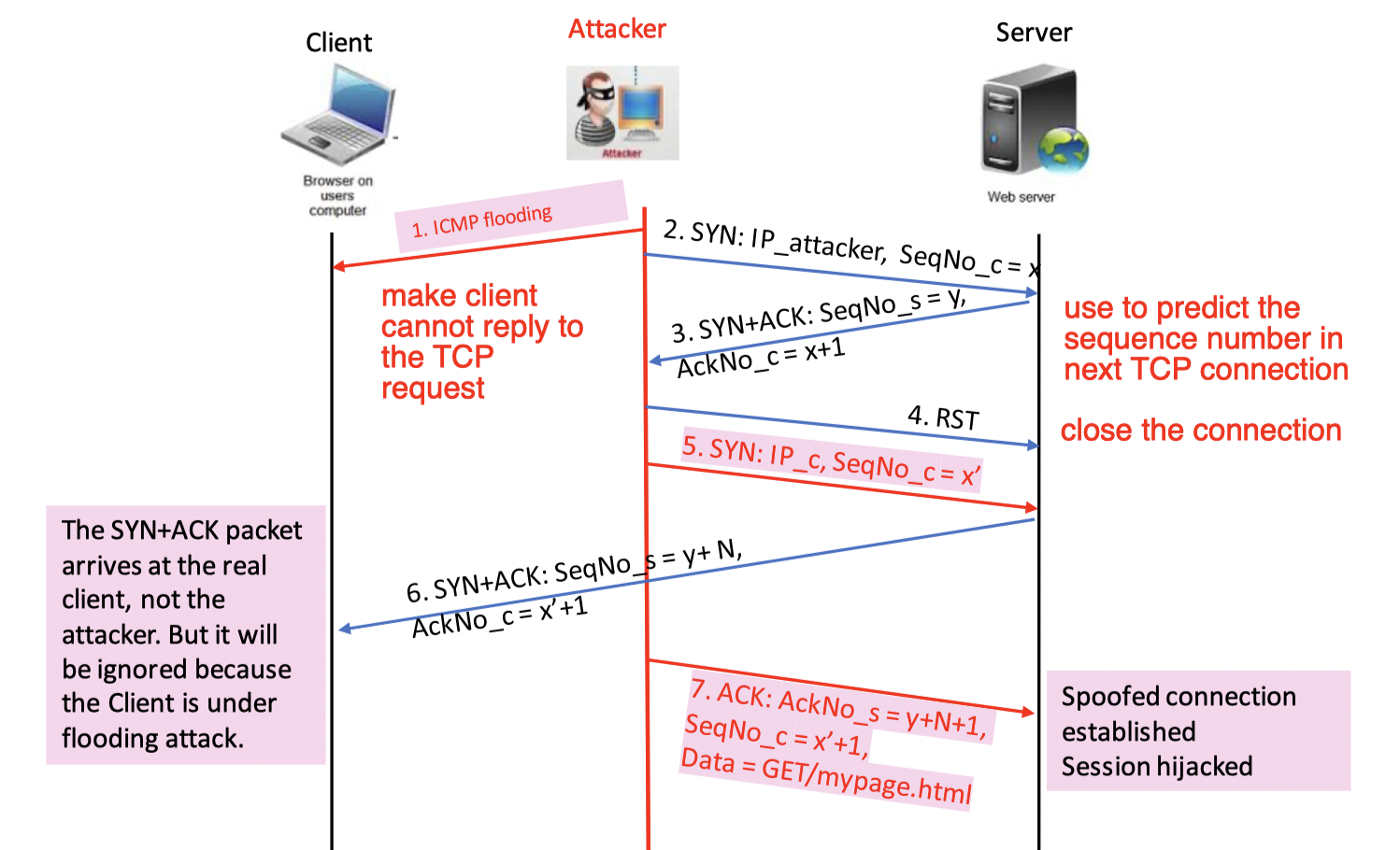
Attacker首先通过flooding使client无法正常工作,然后发起一个新的TCP连接给server,然后通过预测sequence number来伪装成client来进行通信
BGP Route Hijacking
BGP and AS
Border Gateway Procol 也被认为是最重要的Internet协议之一,因为其能够把多个ISPs组织在一起运作
BGP是一个inter-Autonomous System (ASs) 路由协议(用于自治区内部的设备之前通信)
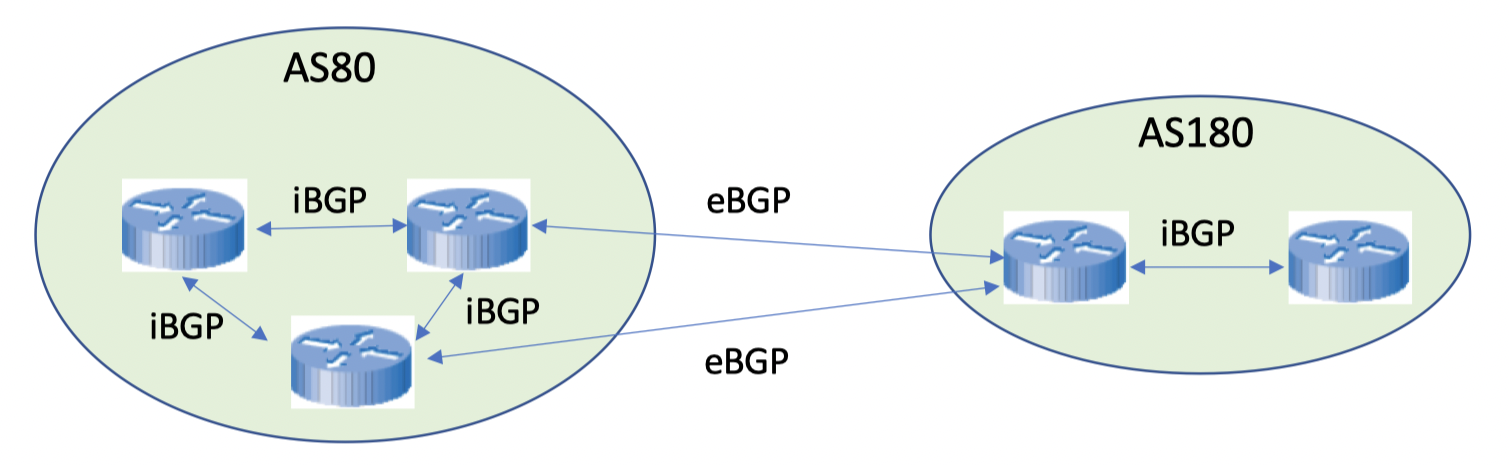
- Autonomous system (AS, 自治系统)
- AS是路由策略中的基本单位,由同一个组织的管理员所管理的所有网络都属于一个AS来作为路由协议的基础
- 每一个AS内部都有很多设备相连,也会有很多的网络
- sometimes referred to as a
routing domain Autonomous System Number (ASN), 每一个AS都有一个,全球唯一
BGP routing table and CIDR prefix
在BGP中,路由并不是直接指定如何到达一个IP地址,而是如何达到一个网段, Classless Inter-Domain Routing (CIDR) prefixes
-
CIDR prefix
CIDR prefix就是subnet mask中含有1的数量
172.16.122.204/16 就位于172.16.0.0/16网段当中,前面16bits为network段,用来指示网段;后面为host段,用来指示具体的主机 CIDR prefix = 16
BGP Routing table 由两部分组成一个entry (x, l):
-
x就是网段
-
l就是路由器的接口interface,指向下一跳的地址

-
-
BGP 的功能
- 从周边的ASs中获取不同的网段的reachability
- BGP允许所有的子网都能宣告自己的存在
- BGP接着会确保所有的路由器都能知道这个子网的存在
- 决定每一个路由器到达不同子网的最优路径
- Policy
- Prefix reachability information
- ASs使用最长掩码匹配机制(longest prefix matching)来选择路径
- 例如当需要决定192.168.20.19的路由时,有两个子网需要选择
- 192.168.20.16/28; 192.168.0.0/16
- 选择192.168.20.16/28,因为其子网掩码长,更具体
- 从周边的ASs中获取不同的网段的reachability
BGP route advertisement and propagation
接着我们具体展开来讲上面提到过的BGP的功能
首先是宣告子网的功能
例如下图,AS22394中有66.174.161.0/24这个子网,于是其开始向外宣告自己有这个子网
然后按照相邻的顺序,AS6167首先收到了这个宣告,然后记录下来6167,22394这个顺序
然后依次继续宣告,并不断记录次序,方便将来路由
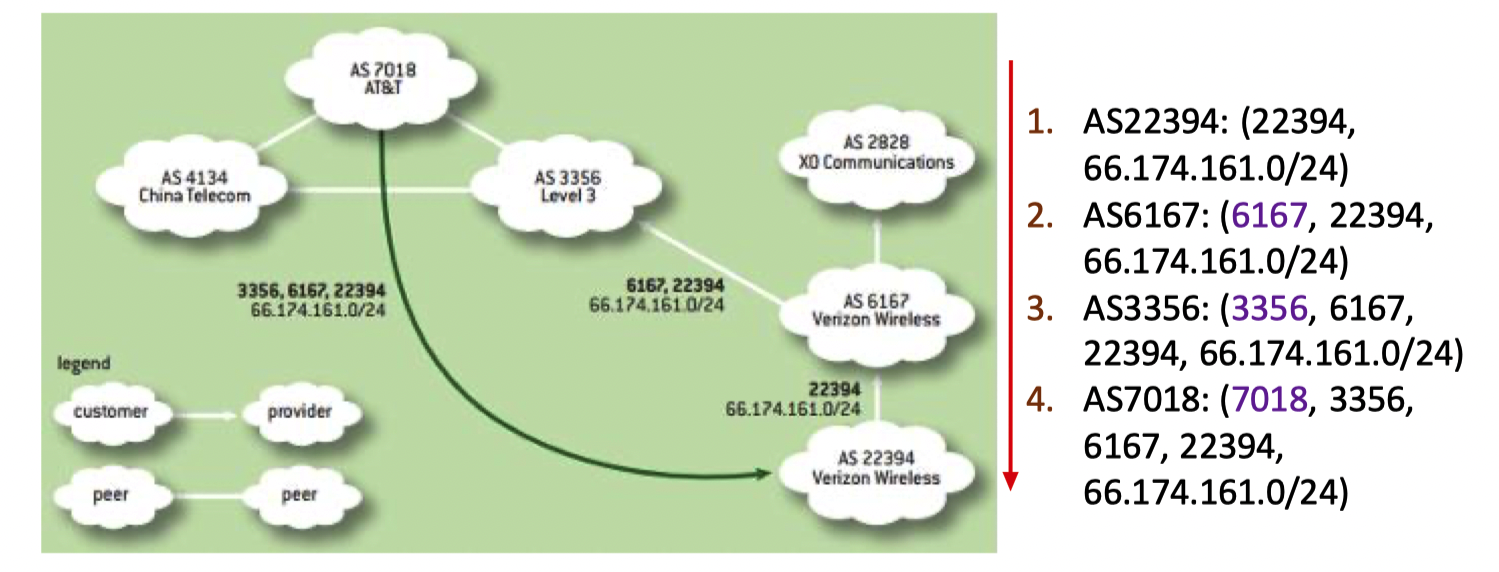
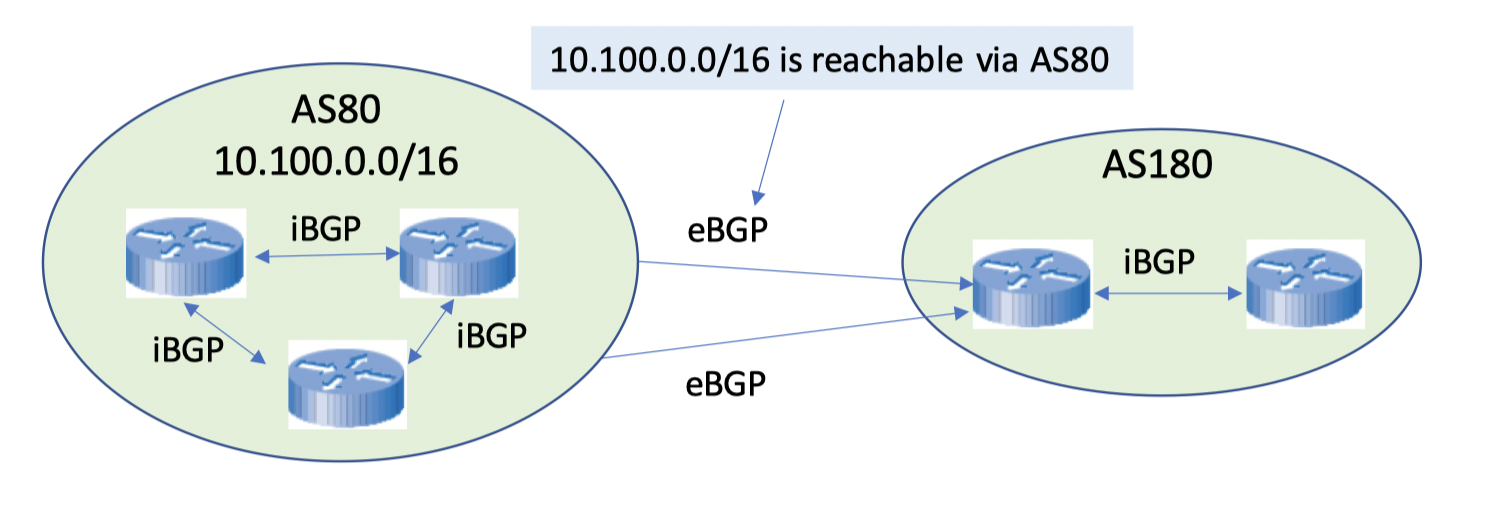
eBGP and iBGP connections
那么AS中也有很多的路由器属于不同的网络,他们之前也会交换子网的信息方便AS内部的路由,因此有内外两种BGP协议来进行路由
-
eBGP, external BGP (TCP),用于不同的AS之前的路由器之间的通信
-
iEBGP, internal BGP (TCP), 用于同一个AS中的路由器之间的通信
BGP route/prefix/sub-prefix hijacking
那么有信息交换,就有hijacking,本质上BGP的hijacking的目的就是通过宣告攻击者的AS能够到达目标子网,来诱使其他的AS将原本将要发送到目标子网的数据发送到攻击者的AS中来。其中也有两种不同的方式
-
BGP route/prefix hijacking
一种是通过直接宣告目标子网在攻击者的AS中的错误信息来误导其他AS将数据发送过来
-
BGP sub-prefix hijacking
就是利用我们之前提到的过的longest matching原则,通过加长子网掩码的长度,诱导AS选择更为确切的子网 例如目标子网为10.100.0.0/16,攻击者就宣告,10.100.0.0/24 来误导其他的AS
BGP routing blackhole and two incidents
How to create a routing blackhole? 如果ASs开始宣告无法提供的子网,那么整一个Internet就会陷入混乱,因为数据包永远无法到达应该发送的位置,也收不到任何的回复
DNS Cache Poisoning
DNS and DNS structure
Domain Name System, DNS
- 一个分布式的数据库用来存储DNS信息,从而完成一个DNS服务器架构
- 一个应用层的协议来向所有主机提供数据库信息
为什么我们需要DNS? 理由也很简单,好记!现在IPv4已经被用完了,取而代之的是更长的IPv6,如果每访问一个网站都需要记住IP地址就太麻烦了
DNS服务器采用树状结构
全世界一共有13个root server
顶级域名Top level domain (TLD)
- com,edu, org, net, gov .etc
- cn, uk, de, eu, etc.
本博客目前的域名后缀后缀就是org.cn
DNS name resolution (iterative and recursive)
DNS主要的作用就是map
- Domain names to IP addresses
- IP addresses to Domain names
DNS resolver向 nameservers 进行mapping请求,一般我们将查询请求分为两种
-
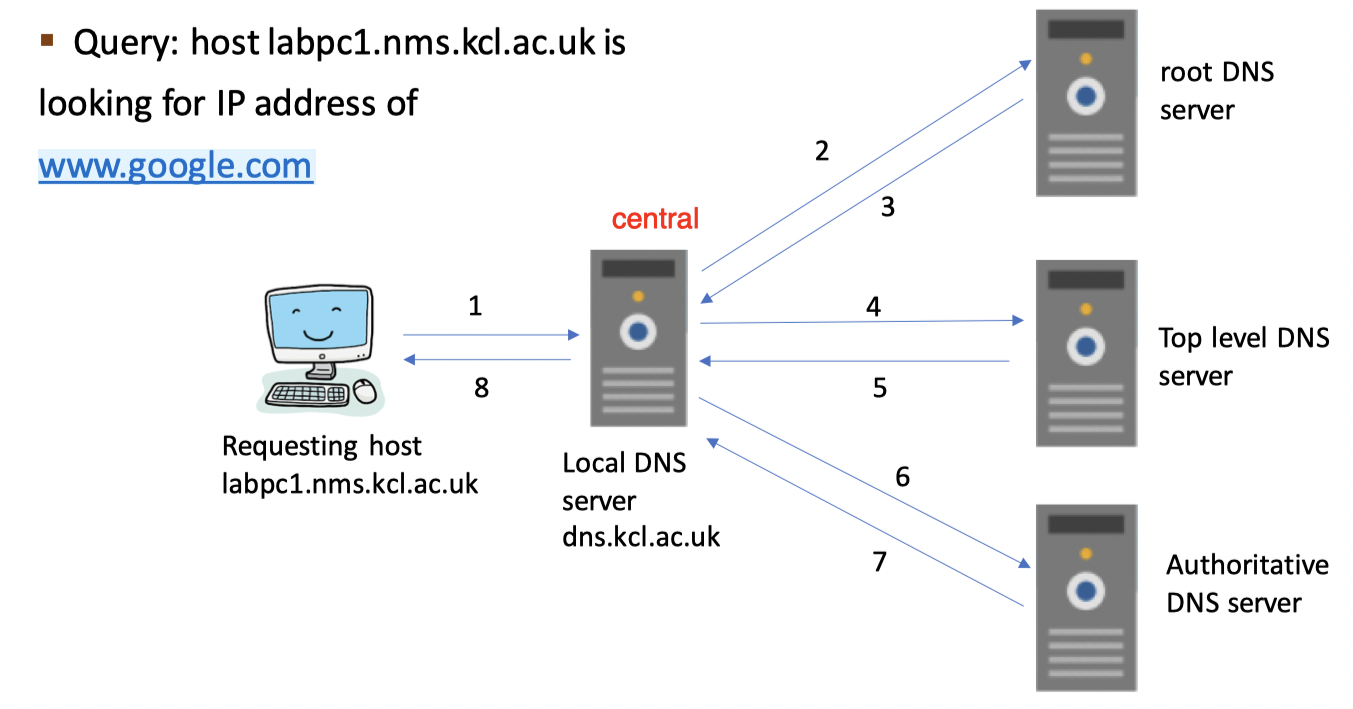
Iterative DNS query with caching 迭代查询
顾名思义就是一个个DNS服务器查过来,一个查不到就下一个
- Local DNS server
- root DNS server
- Top level DNS server
- Authoritative DNS server
-
Recursive DNS query with caching 递归查询
同样也是按次序查询,但是不同的地方在于,只有查到了才会原路返回给用户,否则就会继续将查询递交给下一个服务器
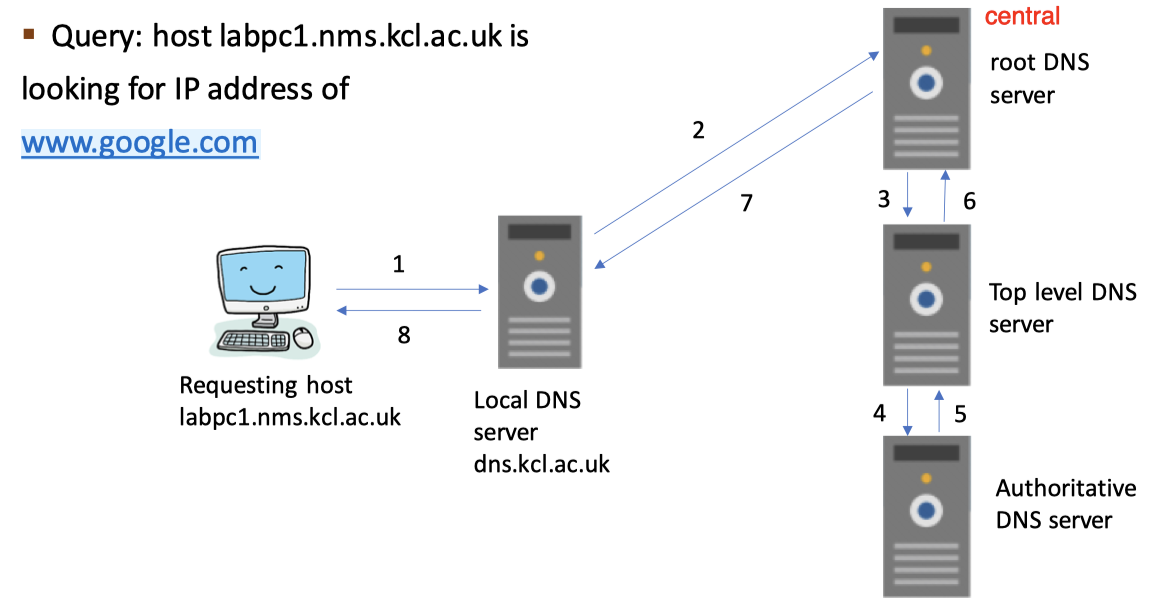
注:一般来说不会在实际中使用
DNS caching
Why we need DNS caching? 通过缓存这些DNS的map信息来加速网页的访问 比如已经查到过一次谷歌的域名和IP地址的map之后,就存在本地的DNS server上,这样下一次就不用花这么多步骤再去查询了
DNS cache poisoning attack
那么这种偷懒的办法也就会遭到黑客的攻击,如果在DNS查询的过程中,黑客发送了伪造的DNS记录给本地的DNS server,那么既而被缓存在本地,造成长久的损害。
同时还会给同一区域的其他设备造成危害,记得之前我们在SCT中提到过的 Water holing attack 就是利用了 DNS cache poisoning attack, 通过获取组织内最频繁访问的页面,就可以利用DNS poisoning来将那个网站改为黑客所构建的恶意网站,既而达到其攻击目的
How DNS poisoning attack works?
那么具体是如何伪造的DNS query回复来使DNS server认为其是合法的查询结构并缓存的呢? 这里也有两种手段
-
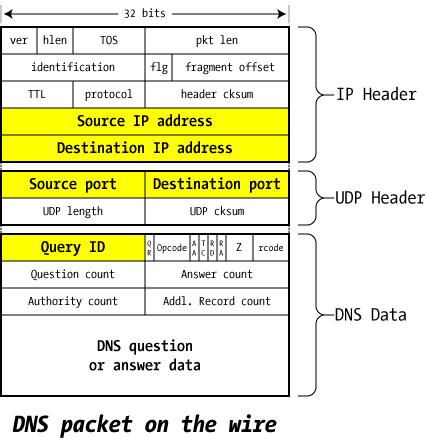
Query QID attack
-
每一个DNS query 都有一个唯一的
QID -
DNS使用UDP进行通信
-
因此不存在连接的说法,只要能够选对正确的QID,就能成功代替真实的回复
-
-
RRSet attack
每一个DNS query response 会包含一组记录集,Resource Record Sets, or RRSets
同时,这些记录集不只包含mapping的entry,还可以增加一些其他额外的信息,对未来的mapping有所“帮助”
比如在一次递归查询中,一般会包含域名的mapping可以在某一个服务器上获得之类的信息,黑客就可以选择篡改这个信息,直接改为mapping的信息,就可以达到其重定向的目的