本文内容主要来源于:Populating the page: how browsers work,再加上本人的理解以及拓展知识的介绍,但是还是建议大家去阅读英文的官方文档,会得到更全面的信息以及拓展资源
快速响应的网站可以为用户提供更好的用户体验,这意味着网站的内容可以:
- 快速的被加载,
- 进行流畅的互动。
那么要实现这两个需求,我们就需要考虑Latency加载等待时间,以及认识到浏览器其实在大多数情况下是 单线程 工作的
Latency, 时延,是我们实现快速响应的主要阻力,为了实现快速响应,降低时延,开发者需要尽可能快的发送请求。
在大部分情况下,浏览器都是单线程在工作的,那么我们为了让网站可以流畅的访问,主要的目标就是保证浏览器的主线程在完成浏览器运行的大部分工作的同时,还有余力来处理用户的交互,那么开发者需要认识到这一点,并且尽量降低主线程所分配到的任务,从而使网页的渲染以及用户的交互更为流畅。
Navigation 导航
导航 是加载网页的第一步,导航发生在当用户通过将URL输入地址栏;点击链接;提交表单以及类似的这样的操作
减少在导航上的时间也是优化网页性能的一个重要目标,阻力来源于时延和带宽
DNS Lookup, DNS 查询
对于网页的导航始于找到资源的位置,也就是通过URL来定位资源,比如我们要访问 https://example.com, 其对应的IP地址是 93.184.216.34, 上面存放着的对应的HTML资源,但是我们的浏览器此时还没有访问过这个网页,因此第一步要做的事情就是DNS lookup;
通过DNS查询,name server最终会返回给浏览器域名所对应的IP地址,进而将其缓存以加速未来的访问速度。
那么我们具体到网页上来,DNS查询不只发生在主页面的HTML的获取上,还需要对HTML上所引用的资源逐一进行导航和DNS查询,这就需要开发者对此进行优化,特别是对于移动端用户,每一次DNS查询都意味着需要通过信号塔来访问授权的DNS server,那么根据信号塔的距离就会产生一定的时延
Figure 1: DNS lookup on Mobile devices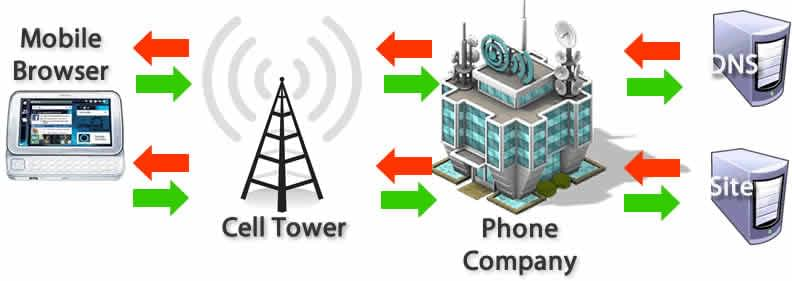
TCP Handshake
经过DNS查询,我们现在已经拿到了目标网页资源所处的IP地址了,接下来就要进行TCP三次握手来进行连接。
通过"SYN, SYN-ACK, ACK" 的三条TCP信息来建立TCP连接。
TLS Negotiation
同时,为了保证安全,我们提倡使用HTTPS协议,其要求在进行基本的TCP三次握手之后,还需要进行进一步的“握手”,来建立安全连接,也就是TLS Negotiation
这将要求额外的5条信息,用来对client以及server进行相互认证,并且确认解码的密钥,来保证数据的保密性
Figure 2: TLS Negotiation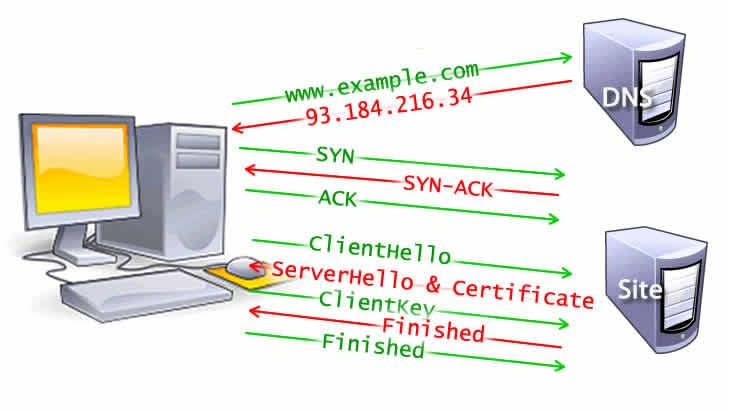
这五条信息可以概括为三个阶段(参考:Bypassing Web-Application Firewalls by abusing SSL/TLS)
- ClientHello/ServerHello 打招呼阶段
- 握手由用户发出clientHello信息开始,这条信息将包含所有服务器所需要的信息,包括cipher suite加密套件(一组算法)以及支持的TLS或者SSL版本;
- 接着服务器端也会返回对应的ServerHello信息包括接下来将要使用的cipher suite以及SSL版本
- Certificate Exchange 证书交换阶段
- 接下来服务器需要向客户端证明自己的身份,于是向客户端发出自己的certificate证书(和serverHello信息一起发出)
- Key Exchange 密钥交换阶段
- 最后为了建立加密的管道,双方需要交换密钥来进行数据的加密和解密
Response 响应
现在浏览器已经和服务器建立了安全的TCP连接了,这时浏览器就会发送一个初始的 HTTP GET request 来请求网页资源,这通常是一个HTML文件,服务器收到了请求,接着返回对应的HTTP headers以及HTML文件的内容
例如:
<!doctype HTML>
<html>
<head>
<meta charset="UTF-8"/>
<title>My simple page</title>
<link rel="stylesheet" src="styles.css"/>
<script src="myscript.js"></script>
</head>
<body>
<h1 class="heading">My Page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myimage.jpg" alt="image description"/>
</div>
<script src="anotherscript.js"></script>
</body>
</html>
Time to First Byte (TTFB) 表示从用户发出请求(点击连接)到收到第一个HTML的数据包的时间,通常第一块信息的大小是14KB的数据
下面我们会解释为什么第一块信息是14KB的。
Congestion control: TCP Slow Start /14 KB rule TCP慢启动
现在已经建立了安全的连接,接下来服务器将会根据用户的请求返回对应的数据,但是传输的速度(单位时间内传输的数据)并不是从一开始就达到最优的速度的,而是慢慢增加的,为的是防止 网络拥塞 。
网络拥塞:网络拥塞就是一个网络节点需要处理大于他们能力的数据时,网络的性能就会变化,也就会发生拥塞,例如路由器或者用户的设备对于接收到的数据的处理速度跟不上接收速度,那么设备的缓存就会被占满,再接收到的数据就会被丢弃,导致网络性能下降。
在网络层就会发生丢包的现象,而主要的拥塞控制就发生在传输层上
TCP慢启动就是一个用来检测数据传输可使用的带宽,同时平衡网络连接速度的算法,其通过逐渐增加数据传输速度来找到最好的传输速度,从而防止 网络堵塞 的发生。
在讲解算法的具体流程之前,我们需要先了解一些相关概念
- congestion window (cwnd)
- 拥塞窗口,发送方的设置,表示在收到接收方ACK之前,发送方最大允许传输的数据大小
- slow start threshold (ssthresh)
- 来设定慢启动算法使用的阈值
- Round-Trip Time (RTT)
- 往返时延,表示从发送方发出数据开始,到发送发收到来自接收方的ACK,所经历的所有时延
- Maximum Transmission Unit (MTU)
- MTU是可以在网络层可以通信的最大PDU的大小,其应用于网络层,单位一般用字节来设定
在以太网中,最大的frame为1518 bytes,其中18bytes是overhead(headers和检查值),MTU的值就是1500 bytes
- Protocol data unit (PDU)
- PDU 是同一层的通信协议之间通信的最小信息单位,例如在OSI模型中:
Layer PDU The Layer 4: Transport Layer segment(TCP)/datagram(UDP) The Layer 3: Network Layer packet The Layer 2: Data link layer frame The Layer 1: Physical layer bit, or more generally, symbol - Maximum Segment Size (MSS)
- 最大TCP segment的大小,是TCP的一个参数
根据定义,我们可以得出:一个TCP segment的payload < MSS < MTU
cwnd < ssthresh,慢启动算法 - 当一个新的连接建立之后,发送方将初始化 cwnd = 1(2013年的RFC6928规定一个cwnd表示10个TCP segment) - 每过一个RTT,即收到ACK之后,cwnd = cwnd * 2,呈指数增长
cwnd = sshtresh 慢启动与拥塞避免算法都可
cwnd > sshtresh,改用拥塞避免算法,我们这里介绍 Additive increase/multiplicative decrease, AIMD算法(加法增加乘法减小算法)
- 在cwnd大于sshtresh之后,每当发送方收到一个ACK之后,++cwnd;呈线性上升,这就是 加法增加
- 一旦出现网络拥塞,就进行 乘法减小 即将 sshtresh = cwnd/2; cwnd = 1
- 接着切换到慢启动算法重新开始
Figure 3: TCP Slow start & AIMD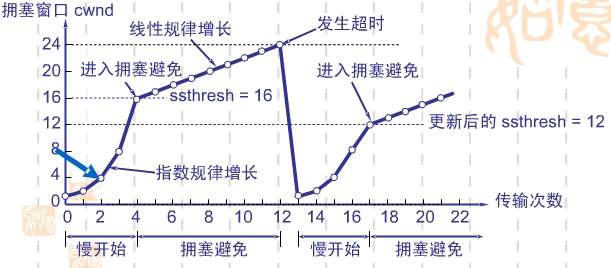
Parsing 解析
当浏览器收到了第一块数据,它就会直接开始解析收到的信息,第一步就是将接收到的数据转换为 DOM & CSSOM, 这两个结构是渲染器用来绘制网页的
DOM, Document Object Model, 是一个用来将XML或者HTML转换为树结构的跨平台,独立于语言的API,可以通过JS调用API来进行修改。
即使请求的HTML文件大于14KB,浏览器仍然会直接尝试解析并渲染第一块14KB的数据,这也就是为什么开发者在做web性能优化的时候,需要将CSS以及HTML控制在14KB之内,以此来保障网页能够成功进行初级渲染。
一个TCP packet最大可以达到1500 bytes,同时其中有40 bytes需要别用作TCP协议(TCP headers),那么也就剩下1460 bytes来承载实际的数据,那么十个TCP packets就是14,600 bytes也就是大约14KB的数据(慢启动一般会从十个TCP数据包开始传输):Critical Resources and the First 14 KB - A Review
接下来我们就会介绍 关键渲染 路径的五个步骤,即浏览器如何将HTML,CSS以及JS转换成屏幕的像素
Building the DOM tree 构建DOM
第一步就是处理HTML标签从而构造DOM树。
HTML的解析涉及到 tokenisation 以及树的构造
我们可以观察下图来看到DOM是如何同通过HTML标签来构造树的:
<html> 是第一个标签,也就是DOM tree的根节点,其他的标签就作为子节点根据对应的结构进行组合
Figure 4: DOM tree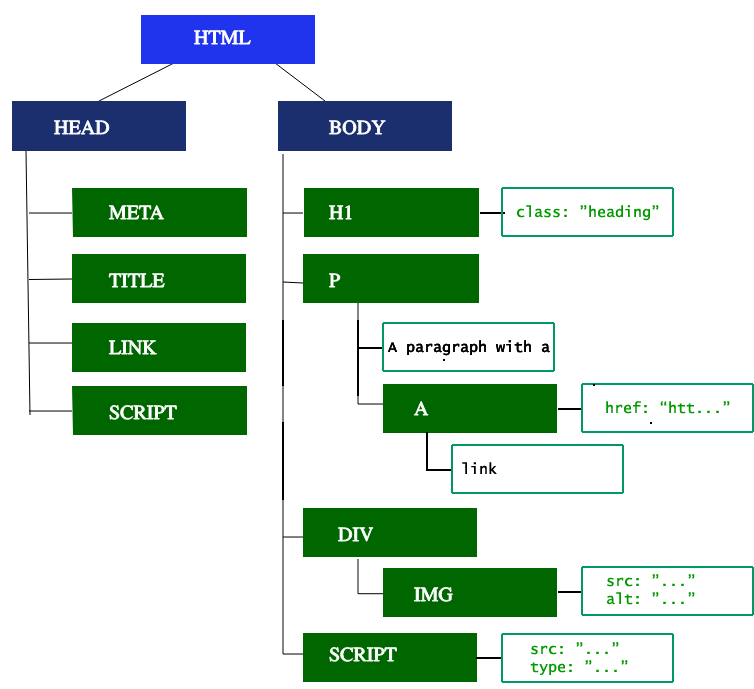
Preload scanner 预加载扫描器
当浏览器在构建DOM tree时,Preload scanner就会占据主线程,并同步开始请求高优先级的资源,以此保证解析不会卡在这些资源的获取上,例如CSS, JS, images, web fonts。
例如下列标签就会在HTML解析的过程中,被preload scanner 所请求获取
<link rel="stylesheet" src="styles.css"/>
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description"/>
<script src="anotherscript.js" async></script>
Building the CSSOM
第二步就是构建CSSOM树,CSSOM树与DOM类似,只不过处理的是CSS而非HTML,通过将CSS规则以及CSS selectors所制定的关系结构转换为一个树的结构
Figure 5: CSSOM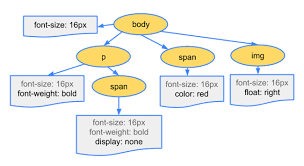
Other Processes
JavaScript Compilation
当CSS在被解析并构建CSSOM的同时,JS文件也在被下载,解释,编译,解析以及执行,这些脚本会被解析并存入 Abstract syntax tree,抽象语法树
Figure 6: AST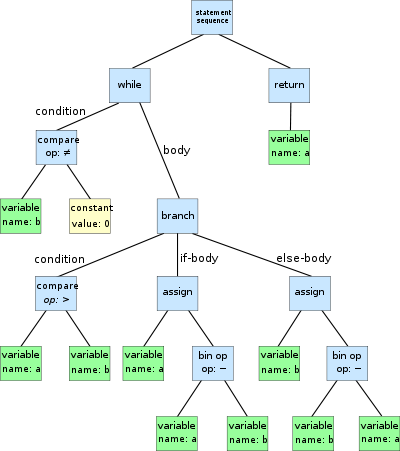
Building the Accessibility Tree 构建辅助功能树
浏览器还会构建 accessiblity tree 来辅助设备来解析和解释内容,accessibility object model (AOM) 拥有与DOM类似的语法结构,AOM一般来说是无法访问的。
在AOM被构建之前,所有的内容都是无法被屏幕阅读器所访问的
那到底什么是Accessibility辅助功能,它有什么作用呢,相信大家都在浏览器的开发者工具里看到过这个功能,甚至在电脑,手机都有看到过这个功能,大概看起来是一个方便disable来使用电子设备的功能,但是我们平时却很少使用。
Accessibility 的目标是使尽可能多的人能够更好的访问网页,不仅仅是有障碍的人士,同时也帮助那些使用移动端设备或者网速很慢的用户群体。
Firefox内置了Accessibility APIs来对网页的内容进行解析,分析不同的元素的功能与角色,从而并构造AOM,同时根据一些网页设计的标准来判断开发是否规范,例如HTML标签是否使用得当,文字的大小,比例,颜色,对比度等内容是否适合与不同的设备,对视力有障碍的人士是否友好。
Firefox官方的一个视频展示了一个很好的例子,对于一个网页的内容,普通人可以进行正常的阅读,但是当这个内容在视力有障碍的人士使用工具进行朗读的时候,也许就会出现问题,这也体现了Accessibility的作用
Render 渲染
渲染的步骤包括计算样式(style),计算布局(layout),最后绘制(paint),在一些情况下还包含了合成。
Style
关键渲染路径的第三步就是将DOM以及CSSOM结合到render tree渲染树/ computed style tree 计算得到的样式树中:
对于每一个DOM树中的可视节点,都会将CSSOM中对应的样式与其配套
Layout
在确定了每一个节点的样式完成渲染树之后,第四步就是要考虑如何对所有的这些元素进行排列,通过从渲染树的根开始遍历,对每个节点的几何信息进行计算,例如宽度和高度,以及在页面中的位置
第一次对于位置以及大小的计算我们称为 layout , 当我们再次确定页面中一些资源的大小例如图片加载完成之后,重新进行计算叫做 reflows 回流
Paint
关键渲染路径的最后一步就是Paint绘制,就是要将所有的可视的内容都绘制到屏幕上去,包括文字,颜色,间距,阴影以及可以替换的元素,例如按钮(按下去的图片)以及图片。
为了保证页面能够流畅的滚动以及动画效果,Paint将占据主线程来进行绘制,为了确保绘制的速度,屏幕上的绘图通常会被分解称数层来进行,那么同时也就需要进行合成。
绘制会讲layout tree 中的元素分成多层,将内容提升到GPU可以提高绘制和宠幸绘制的性能:有一些特定的属性和元素可以组成一个层(例如<video>, <canvas>);CSS属性为opacity、3D transform、 will-change的元素,也可以组成单独的层来进行绘制,不过这也意味着需要消耗更多的内存,注意不能过度使用
Compositing 合成
那么在Paint的过程中分层进行之后,就需要对所有的层进行合成,相互重叠,保证它们以正常的顺序绘制到屏幕上,显示正常的内容。
Figure 7: Critical rendering path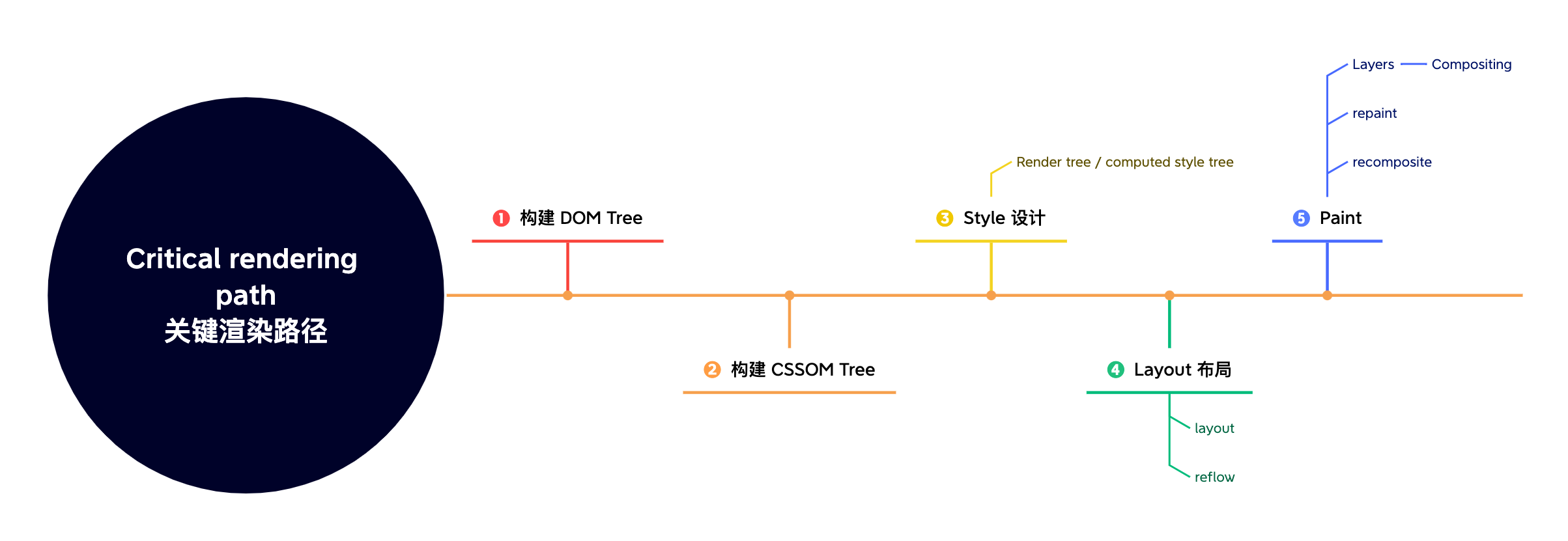
Interactivity 交互
主线程绘制页面的任务完成并不代表一切都准备就绪,还需要加载JavaScript脚本(比如onload属性就是等待给定的资源加载完成时触发),那么在加载JS的过程中,记得我们的浏览器大部分还是一个单线程,因此就无法进行滚动、触摸或者其他的交互
我们用 Time to Interactive (TTI) 来衡量从第一个请求所触发DNNS查询开始到页面可以正常教务所使用的时间,页面需要在50ms,如果此时主线程还在解析,编译和执行JS就会导致页面不不能相应用户的交互,这就是需要调整的地方。
后记
对于浏览器原理的学习源于在SSTI模版注入的学习中,在我想要搞清楚模版引擎的作用和意义的时候,很多博客中不断出现一个既陌生又熟悉的字眼:“渲染”,于是就想要探寻一下完整的WEB的工作框架,在一番学习之后,貌似学到了很多东西,但是又同时也带来了更多的疑问。
在这个过程中也暴露了我在CTF WEB方向学习中的一个弊端,就是往往一些简单的题目更多的是在考验对于漏洞的理解和利用,但是实现的场景非常的原始,往往都是整一个HTML返回到前端,这肯定是与真实场景所不符合的,我觉得我应该对开发有更深刻的理解,才能更好的去发现漏洞。比如在模版引擎的学习中,提到很多的例子就是查询,于是当我尝试去Google一个东西,在看到Burp返回之前,我都不确定返回过来的内容应该是完整的页面还是一个HTML框架加上JS脚本来获取进一步的数据,更别说其背后协作的原理。
那么在后记中我还想对于渲染以及上述提到的浏览器工作原理中扩展内容进行一些补充,因为我发现我现在只是有一个大概的了解,但好像还是理解的不那么充分。
脚本和样式文件对于页面渲染的影响
本章内容主要参考:浏览器是如何渲染页面的?
脚本文件对于页面渲染的影响
在解析HTML标签的过程中,我们知道浏览器会将从服务器所获取的文档自上而下进行解析,在文档中的<script>标签不含 defer 以及 async 属性的情况下,浏览器会根据以下规则进行操作:
- 解析HTML文档,遇到HTML标签,构建DOM树
- 构建DOM的过程中,如果遇到外部的样式文件或者脚本文件的申明,暂停当前文档的解析,创建新的网络连接,开始下载样式文件和脚本文件。原因就是我们之前提到的,浏览器在大部分时候都是单线程工作的。
- 样式文件下载完成之后,就开始构建CSSOM;脚本文件下载完成后,解释并立即执行
我们可以通过一个例子来演示这个中断
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<script type="text/javascript" src="defer.js"></script>
</head>
<body>
body render!
</body>
</html>
head中过所加载的脚本文件为
alert('I am the script');
Figure 8: Load and execute script before render
我们可以观察到,根据html文档的顺序,浏览器会先加载JS脚本,并且在脚本加载完毕之后直接执行,也就是跳出提示框,接着才能重现回来解析HTML并且渲染最终body的内容
很显然,这种中断不是用户所想要看到的,因此开发者应该合理的使用 <script> 标签中的 defer & async 属性来调整脚本的下载和执行的顺序,使其不会阻塞页面的加载
- defer:开启新的线程下载脚本,并且在文档解析完成之后立即执行脚本
- defer只适用于外联脚本(需要加载的js文件),如果 <script> 标签没有指定
src属性,就只是内联脚本,不需要使用defer - 如果有多个申明了的defer外联脚本,则会按照顺序加载和执行
- defer外联脚本会在
DOMContentLoaded和Load事件之前执行
- defer只适用于外联脚本(需要加载的js文件),如果 <script> 标签没有指定
我们利用下面的例子来进行测试
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<script type="text/javascript" src="defer1.js" defer></script>
<script type="text/javascript" src="defer2.js" defer></script>
<script type="text/javascript" defer>
console.log('使用了defer属性的内联js')
</script>
</head>
<body>
<script type="text/javascript">
document.addEventListener("DOMContentLoaded", function() {
console.log('DOMContentLoaded');
}, false);
window.addEventListener('load', function() {
console.log('onload');
}, false);
</script>
</body>
</html>
defer1.js:
console.log('defer1');
defer2.js:
console.log('defer2')
我们可以观察到html一共有4个脚本,全部都打上了defer属性,但是其中只有 defer1.js & defer2.js 两个文件是外联的,因此我们可以观察脚本执行的顺序,首先内联的脚本会在解析body中的内容之前就被加载与执行,defer1.js & defer2.js会在DOMContentLoaded & Load事件之前执行
Figure 9: 内联脚本使用defer
- async: 异步下载脚本文件,下载完毕之后立即解释执行代码,是HTML5新增的属性
- 只适用于外联脚本文件,于defer一致
- 如果有多个async的脚本,每一个脚本都会开启一个新的线程,因此它们的下载和执行都是异步的,不能确保彼此的先后顺序
- async会在load事件之前执行,但是不能确保与DOMContentLoaded的执行显示顺序
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<script type="text/javascript" src="async1.js" async></script>
<script type="text/javascript" src="async2.js" async></script>
<script type="text/javascript" async>
console.log('使用了async属性的内联js')
</script>
</head>
<body>
<script type="text/javascript">
document.addEventListener("DOMContentLoaded", function() {
console.log('DOMContentLoaded');
}, false);
window.addEventListener('load', function() {
console.log('onload');
}, false);
</script>
</body>
</html>
async1.js:
console.log('async1.js')
async2.js:
console.log('async2.js')
我们可以根据下面三次的结果观察到:
- async对于内联的脚本无效,仍然会占据浏览器的主线程进行加载和执行
- async会在onload之前发生
- async与DOMContentLoaded的执行顺序不确定
- async外联脚本之前的执行顺序不确定
Figure 10: 在DOMContentLoaded之后执行
Figure 11: 在DOMContentLoaded之前执行
Figure 12: async外联脚本的执行顺序不确定
下面的图很好的总结了内联,以及两种外联脚本的加载与执行的顺序以及与HTML解析的关系:
- 内联脚本会中断HTML的解析(绿色),转而加载(蓝色)以及执行(红色),完成之后再重新开始HTML解析
- defer外联脚本则是开启新的线程去加载,并且在文档解析完成之后立即执行
- async外联脚本会开启新的线程去加载,不会中断HTML的解析,但是加载完成之后立即执行,此时会中断HTML的解析
Figure 13: normal, defer, async脚本加载执行的过程
综上所述,我们知道了 defer & async 属性都可以防治外联脚本的加载阻碍页面的渲染,如果外联脚本之间没有依赖以及顺序关系,可以使用async,反之则可以使用async。如果不想使用这两个属性,直接将所有的脚本放在 </body> 也就是HTML页面内容结束之前,也可以达到相同的效果。
样式文件对于页面渲染的影响
我们在正文中的提到过在解析Parse阶段的时候,浏览器会解析HTML并构建DOM树,同时也会解析CSS来构建CSSOM树,这里我们具体来讲讲对于CSS的处理会如何影响页面的渲染。
- 如果CSS文件放在
<head>标签中,也就是<body>之前那么CSSOM树就会先被解析和构建,那么当浏览器开始解析和构建DOM树时就可以顺便完成渲染; - 但是如果CSS放在所有页面标签之后,比如
</bdoy>之前,那么只有当DOM树构建完成之后,CSSOM树才开始构建,渲染树也的构建时间也需要延后,这就回导致浏览器不得不重新渲染整一个页面,造成了资源的浪费,也会让页面内容出现混乱,一切都要等待CSS加载完成,页面完成重绘之后才能回复。
因此,脚本和样式文件的位置都需要权衡其利弊,来决定是应该放在顶部提前解析/执行,还是放在底部来让出资源。
回流和重绘
- Reflow 回流
- 第一次确定网页节点的几个位置称为布局(layout),第二次重新计算尺寸以及位置叫做回流(reflow)。
比如第一次的布局已经完成,此时图片又加载完成,那么渲染树就需要重新计算每个节点的尺寸、位置,此时就会触发reflow操作,重新构建渲染树
那么在触发回流的同时,就势必会触发repaint(重绘)以及recomposite(重组)
- 会触发reflow的操作
- Reflow的成本要比Repaint来的高,DOM树的每个节点都会有一个reflow方法,一个节点的reflow可能造成一连串依赖节点的reflow,如果发生在移动端设备上,这个过程将是耗时耗电的:
-
增加、删除、修改DOM节点
-
移动DOM的位置
-
绘制动画
-
修改CSS样式
-
Resize窗口或者滚动窗口
-
修改网页的默认字体
-
display:none会触发reflow; visibility:hidden只会触发repaint,影响较于reflow更小
-
- Reflow的成本要比Repaint来的高,DOM树的每个节点都会有一个reflow方法,一个节点的reflow可能造成一连串依赖节点的reflow,如果发生在移动端设备上,这个过程将是耗时耗电的:
我们如何才能将reflow对于性能的影响减到最小呢?
-
不要逐条修改DOM样式,可以预先定义好css的class,然后修改DOM中的className
// 不好的写法 var left = 10, top = 10; el.style.left = left + "px"; el.style.top = top + "px"; // 推荐写法 el.className += " theclassname"; -
将DOM进行离线修改:先用
documentFragment对象在内存中操作DOM,将其设置为display:none触发reflow与repaint,再完全修改完成之后,再显示出来,这样就不会重复触发reflow;或者可以克隆一个DOM节点到内存中,修改完成之后再整一个与当前的DOM进行交换 -
不要使用table布局,因为可能会因为一个很小的改动就造成整一个table的重新布局
onload事件和DOMContentLoaded事件
DOMContentLoaded 事件,顾名思义,就是要等DOM构建完成,即HTML文档被完全加载和解析之后触发的事件,无需等待样式,图片,自框架的记载
onload 事件则是需要等待所有的元素,包括图片以及脚本等全部加载完成之后才会触发,也就是会晚于DOMContentLoaded执行,我们通过之前的例子也可以观察得到onload永远是在最后发生的。
因此,在页面的图片很多,网络不好的情况下,用户从导航到onload事件的触发需要很长的时间,如果此时在onload中加入很多初始化的动作,势必会影响用户的体验,这时就需要用DOMContentLoaded时间来代替onload事件才是更合适的。
前端页面渲染的几种方式(CSR/SSG/SSR)
本章内容主要参考:前端页面渲染的几种方式(CSR/SSG/SSR)
接着我们来了解一下页面渲染的几种基础的模式
客户端渲染 CSR (Client Side Render)
客户端渲染,顾名思义就是页面的渲染会在客户端的浏览器中进行,我们常见的react, vue单页应用框架就是使用了客户端渲染。
浏览器访问网页,服务器会先返回html的内容,并开始构建DOM树,CSS样式以及JS脚本将会在DOM树构建完成之后再进行加载,进而改变DOM树的结构,完成渲染。
CSR就比较适用于单页应用(single page applications, SPA),还有用户交互比较多的应用(比如游戏),因为涉及到大量动态的数据获取,比如表格,聊天内容等
| Pros | Cons |
|---|---|
| 服务器相应速度快,原始html,js,css返回给浏览器就可以了 | 在js得到渲染之前,页面中没有内容,出现白屏,降低用户体验 |
| 对于页面交互、单页应用比较友好,因为其在动态内容的加载方面比较方便 | 页面渲染代码在JS中,爬虫不能解读,对于SEO(Search Engine Optimised)引擎不够友好 |
爬虫主要分为低级爬虫和高级爬虫两种:
- 低级爬虫:只请求URL,URL返回的HTML是什么就爬取什么内容(CSR中的HTML并不是完整的页面信息,还需要进行JS获取后才能结合渲染)
- 高级渲染:请求URL,加载并执行JS脚本渲染页面,爬取渲染后的内容
Figure 14: CSR 客户端渲染流程 1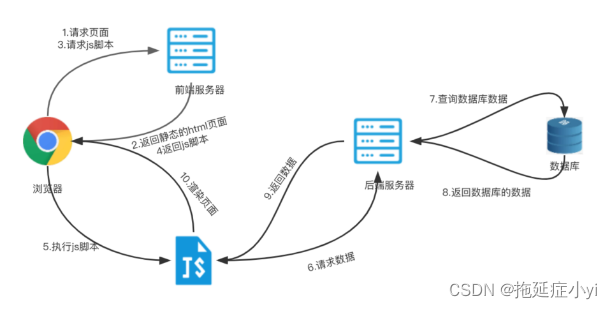
Figure 15: CSR 客户端渲染流程 2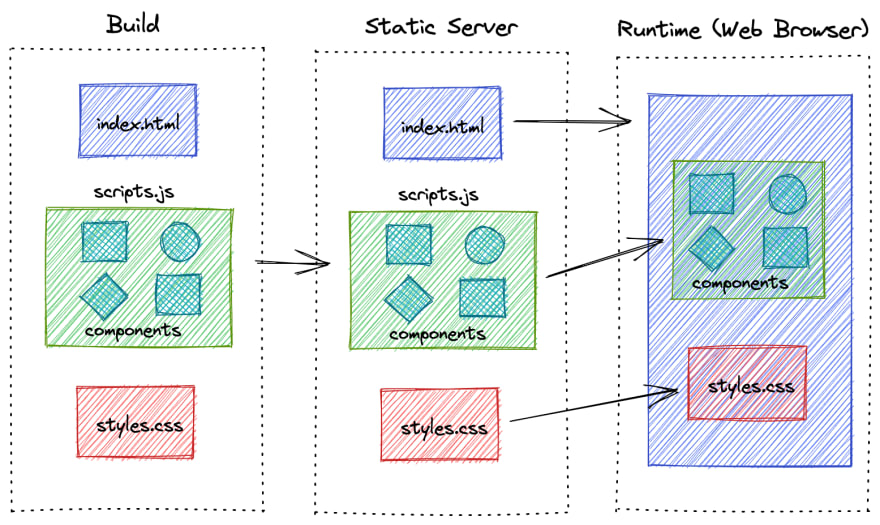
服务端渲染 SSR (Server Side Render)
SSR较于CSR,最大的区别就是其在服务端就先对页面进行渲染,每次当用户请求访问一个页面的时候,都会向服务器发送请求,并动态渲染完成页面(结合HTML,CSS以及CS)后再传回给浏览器,因此相应的时间势必会加长。
Figure 16: SSR 服务端渲染流程 1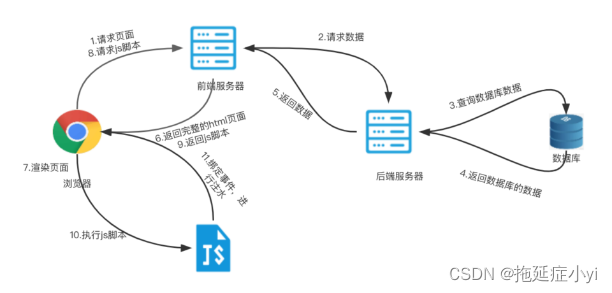
Figure 17: SSR 服务端渲染流程 2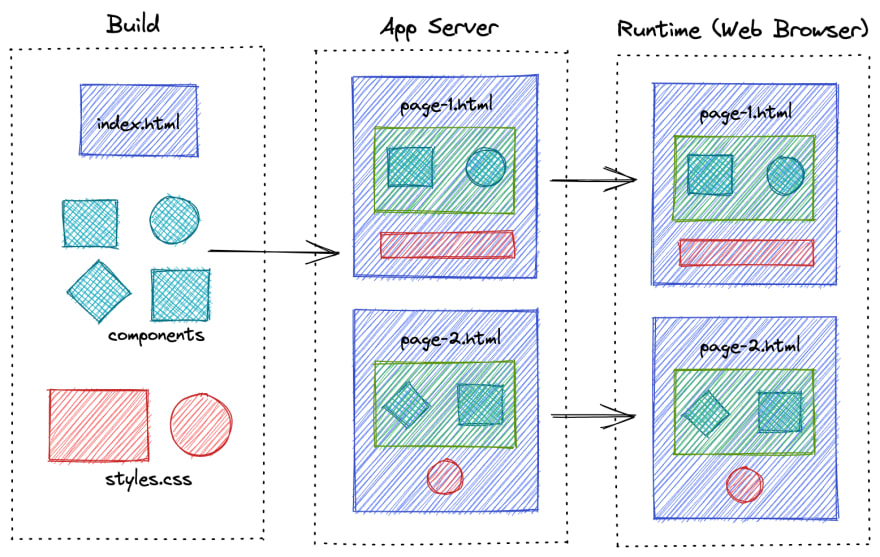
| Pros | Cons |
|---|---|
| 拥有良好的SEO(因为返回的都是完整的HTML页面,可供爬虫读取) | 因为需要再服务端进行完整的渲染和数据处理后才会返回,因此服务器响应时间很长 |
| 支持页面交互 | 服务端维护成本更高 |
图片中提到的注水和脱水操作,可以参考这里,这里就不详细展开了
静态页面生成 SSG (Static Site Generation)
静态页面与前面两种渲染不同的地方就在于,其无法完成交互,只有静态的内容展示,就比如我们的博客,架设在github.io上,每次提交之后就会自动生成完整DOM的html页面供浏览器访问。
| Pros | Cons |
|---|---|
| 拥有良好的SEO(与SSR的原理相同) | 不支持页面交互 |
| HTML包含渲染的DOM,加载更快 | 构建过程中没有window,document等,存在兼容问题 |
Figure 18: SSR 静态页面生成流程 1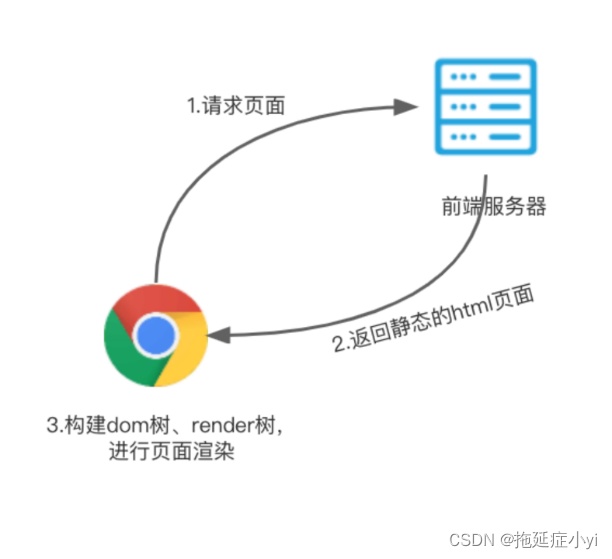
Figure 19: SSR 静态页面生成流程 2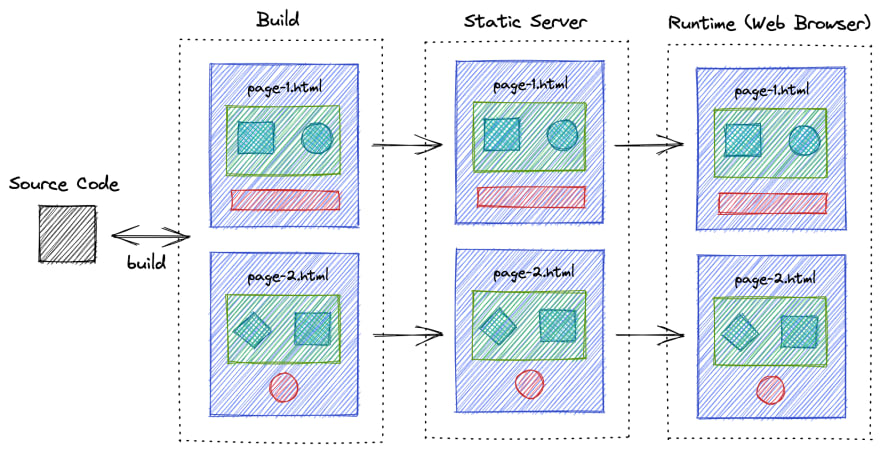
Reference
Populating the page: how browsers work